Débrief React Paris 2025

Écrit par : Bastien Dufour | Pierre-Emmanuel Denys
Relu par : Théo Lanord | Nicolas Zago
Débrief React Paris 2025
React Paris est un événement organisé par BeJs, association d’origine belge déjà à l’origine des événements React Brussels, React Africa et BeJS Conf. BeJS a été fondée en 2019 avec pour mission de présenter des conférences JavaScript dans des régions sous-représentées comme la Tunisie et le Maroc.
React Paris, comme les autres conférences BeJs, met en avant la diversité des intervenants grâce à des appels à propositions anonymisés, avec des règles privilégiant les speakers internationaux intervenants pour la première fois tout en faisant la part belle à la représentation locale.
En outre, les talks sponsorisés y sont interdits et sont single-track.
Les speakers et les sujets
React Paris 2024 nous avait offert le plaisir de voir des talks de Josh W. Comeau et d’Anthony Fu. S’étalant sur deux jours, React Paris 2025 promettait de belles conférences avec notamment la participation de Kent C. Dodds, TkDodo (maintainer TanStack/query) et David Khourshid (créateur de XState). En outre, des talks sur l’accessibilité (Kateryna Porshnieva), les d_esign systems_ (Yu Ling Cheng, Jean Burellier), les React Server Components (Aurora Scharff), le testing côté frontend (Violina Popova, Kate Marshalkina) mais aussi la clean architecture dans un projet Remix (Antoine Chalifour) ainsi que le rôle de l'IA dans l'écosystème React (Tejas Kumar) étaient au menu de ces deux jours.
La grande majorité des conférences étaient de qualité et faisaient la part belle à des sujets et des approches variés. Pour cette année, nous vous proposons d’entrer dans le détail de quelques conférences relatives à l’écosystème front (bien que mon cœur t’appartiendra toujours cher petit framework au logo de molécule ⚛︎) :
- les dernières nouveautés CSS
- l’accessibilité
- les React Server Components
- la naissance d’une nouvelle stratégie de tests incluant des champignons
- comment mal utiliser un framework front
- les mathématiques à la rescousse des développeurs front
CSS’s not dead
I Can’t Believe It’s Not JavaScript
Depuis quelques années les conférences mettant en avant les nouvelles fonctionnalités CSS fleurissent. Jemima Abu revient dans son talk sur quelques unes de ces avancées qui permettront, quand la feature ne sera pas disponible depuis seulement 3 mois ou expérimentale, d’implémenter des pop-over, des modal, des accordéons voire des animations de scroll sans avoir à écrire de JavaScript.
C’est une bonne nouvelle, les implémentations en JavaScript pour ces éléments UI étant souvent impératives et assez bancales. Heureusement, Jemina Abu nous rappelle que dès maintenant il est possible d’utiliser le fantastique sélecteur CSS :has pour, notamment, cibler un parent en fonction de ses enfants 🤯.

I <3 HTML
Demystifying Accessibility in React Apps
L'accessibilité est un aspect crucial du développement web moderne, garantissant que les applications peuvent être utilisées par tous, y compris les personnes en situation de handicap. L’accessibilité ça n’est pas que pour les autres, c’est aussi pour soi plus tard.
Soyons donc un peu égoïste et ne demandons pas la permission pour écrire du code accessible, après tout le faisons-nous pour écrire du code propre ?
Lors de sa conférence, Kateryna Porshnieva rappelle les outils courants utilisés par les personnes en situation de handicap (lecteurs d’écran, voice control, etc.) et présente plusieurs outils et techniques pour améliorer l'accessibilité des applications React. Elle insiste notamment sur :
- l’importance du HTML et de sa sémantique
- le recours à
ARIA(Accessible Rich Internet Applications soit« un ensemble de rôles et d’attributs qui définissent comment rendre le contenu et les applications web accessibles pour les personnes avec des handicaps ») lequel peut parfois poser plus de problèmes qu’il n’en résout s’il est mal utilisé
L'importance de l'HTML
Tout commence avec le HTML. La structure HTML se transforme en arbre DOM, puis en interface utilisateur visuelle. L'arbre d'accessibilité, exposé aux technologies d'assistance et accessible aux dev tools, est également créé à partir de cette structure.
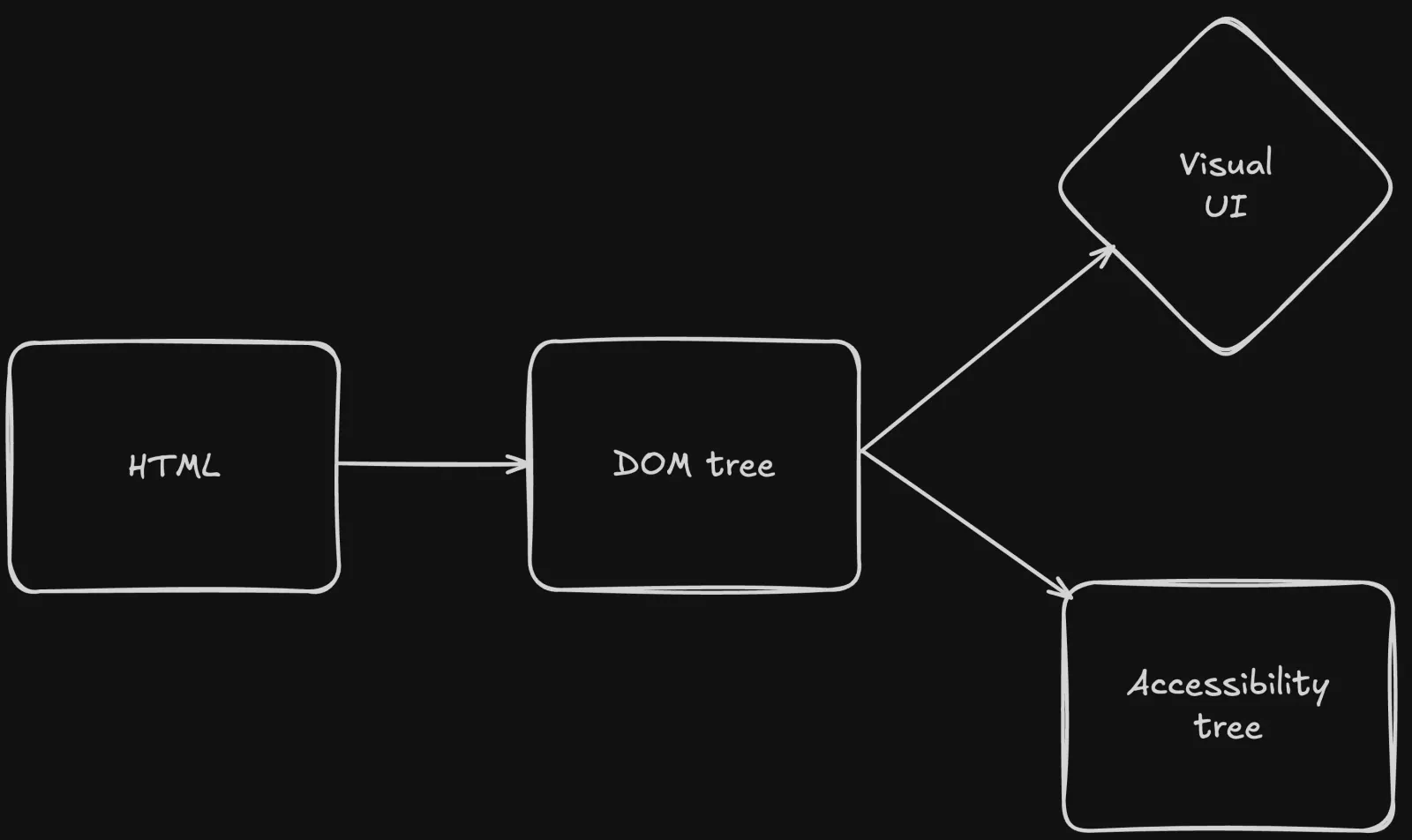
Sémantique et ARIA
La sémantique HTML joue un rôle essentiel en transmettant le sens des éléments. Cependant, dans les interfaces modernes, les balises HTML peuvent ne pas suffire. La boîte à outils d’ARIA vient en aide en modifiant la signification des éléments HTML.
Prudence toutefois car la spécification ARIA recommande son utilisation uniquement lorsque la sémantique HTML ne permet pas de répondre à un besoin spécifique car, paradoxalement, les sites qui utilisent ARIA ont 34 % d'erreurs d'accessibilité en plus par rapport à ceux qui n'en font pas usage (source).
Ainsi, transformer une <div> en bouton en lui ajoutant le rôle adéquat :
<div role="button">click</div>
n’est pas une solution miracle : appliquer role="button" à une div implique de fournir les fonctionnalités attendues d'un bouton à cet élément en plus de la simple indication de son rôle.
Quelques éléments de la boîte à outils d’ARIA
Parmi les bonnes pratiques évoqués par Kateryna Porshnieva, on compte :
- l’attribut
aria-hidden, utile pour masquer les éléments décoratifs, évitant qu'ils ne perturbent l'expérience utilisateur des lecteurs d'écran. Attention toutefois au recours àaria-labelpour les boutons en forme d’icône puisque ces labels ne peuvent être traduits automatiquement. On préférera cacher visuellement le label (.sravec Tailwind par exemple) - une bonne gestion du focus en ayant recours à
:focus-visibleplutôt qu’au destructeur *:focus { outline: none; }— le navigateur se chargeant de gérer intelligemment le focus visible ou non :not(:has(:focus-visible))pour la gestion des éléments apparaissant au hover associé à l’utilisation de media queries ciblant les écrans tactiles- pour les formulaires, les recommendations sont nombreuses et de bon sens. On citera la génération d’
idunique avec le hookuseIdde React, l’utilisation astucieuse dearia-describedbypour contrebalancer le support hésitant dearia-errormessageet un peu de politesse avec les notifications dynamiques grâce àaria-live="polite"pour les notifications non urgentes.
Enfin, Kateryna Porshnieva rappelle qu’un code accessible, c’est aussi des tests front plus robustes !
const usernameError = screen.getByRole("alert", {
name: /username is too short/i
});
expect(usernameError).toBeInTheDocument();
expect(username).toBeInvalid();
Concernant le test de l’accessibilité en elle-même, Il existe plusieurs outils comme axe DevTools, Lighthouse et le plugin ESLint jsx-a11y. Enfin, des testeurs spécialisés peuvent être recrutés sur des plateformes comme Fable.
RSC : pas de client, pas de problème
React Server Components: Elevating speed, interactivity, and user experience
Voilà une démo impressionnante d'une application Todo réalisée par Aurora Scharff avec les composants serveur de React (RSC) – sans utiliser useEffect ni useState. L'application finale s'affiche rapidement et répond rapidement, malgré des temps de réponse simulés côté backend vraiment très longs.
Présentation de RSC
Les RSC s'exécutent côté serveur ou au moment de la compilation, sans dépendre des API du navigateur, de l'état ou des effets. Brièvement, ses avantages sont les suivants :
- Réduction de la taille du bundle. La taille du bundle envoyé au client est réduite, ce qui améliore les performances lors du chargement des pages
- Récupération asynchrone des données. Les données sont récupérées de manière asynchrone depuis le composant lui-même, sans attendre que le composant soit monté côté client et sans devoir gérer un état local
- Accès direct aux ressources du backend. Les ressources du backend sont accessibles directement puisque les appels sont exécutés côté serveur.
- Report du rendu et progressive enhancement. Les composants non essentiels au chargement de la page sont rendus au besoin, avec une UI de chargement (
<Suspense>), divisant le coût des requêtes réseau et du rendu entre client et serveur.
Et côté code ?
Disponible depuis React 19, le hook use est utilisé pour rendre de manière asynchrone un composant client qui prend une promesse en propriété, utile lorsque le composant a besoin d'accéder à des API du navigateur (et doit donc être un composant client) mais que le parent est un composant serveur qui ne doit pas bloquer le rendu pour des données dépendantes.
React 19 introduit également useOptimistic pour rendre l'interface utilisateur sans attendre la réponse asynchrone. Aurora Scharff insiste également sur la pertinence d’utiliser cache (toujours en canary au premier semestre 2025) :
- pour mettre en cache des requêtes/coûteux calculs, permettant le pré-chargement de données côté serveur (cf. la documentation de React à ce sujet)
- et, plus important encore, pour conserver le caractère composable des composants : deux composants peuvent appeler le même service API, sans redondance, les données récupérées par le premier seront réutilisables pour le deuxième
L'amélioration progressive (progressive enhancement) est également possible via le composant <Form> de Next.js, qui repose sur HTML plutôt que sur JavaScript.
Enfin, le talk se termine sur quelques bonnes pratiques liées à l’utilisation des RSC :
- résoudre les promesses le plus profondément possible dans l'arbre de composants et non au plus haut niveau de la page (👉
getServerSideProps) → ne bloque plus le rendu - les indicateurs de chargement avec interface utilisateur adaptée deviennent capitaux pour le cumulative layout shift et par extension pour une meilleure expérience utilisateur
- utiliser l'URL comme source de vérité de l'état de l'application (cf. l’excellent talk de François Best « Type-Safe URL State Management in React with nuqs »)
Champignon testing de Paris
At the top of the pyramid: Playwright testing at scale
Kate Marshalkina fait un chouette retour d’expérience sur une codebase chaotique, très partiellement écrite en TypeScript et avec des tests peu efficaces.
Une petite histoire des stratégies de test
Kate revient d’abord sur les patterns pratiqués dans l’industrie :
La pyramide de test proposée par Mike Cohn et revue par Martin Fowler :
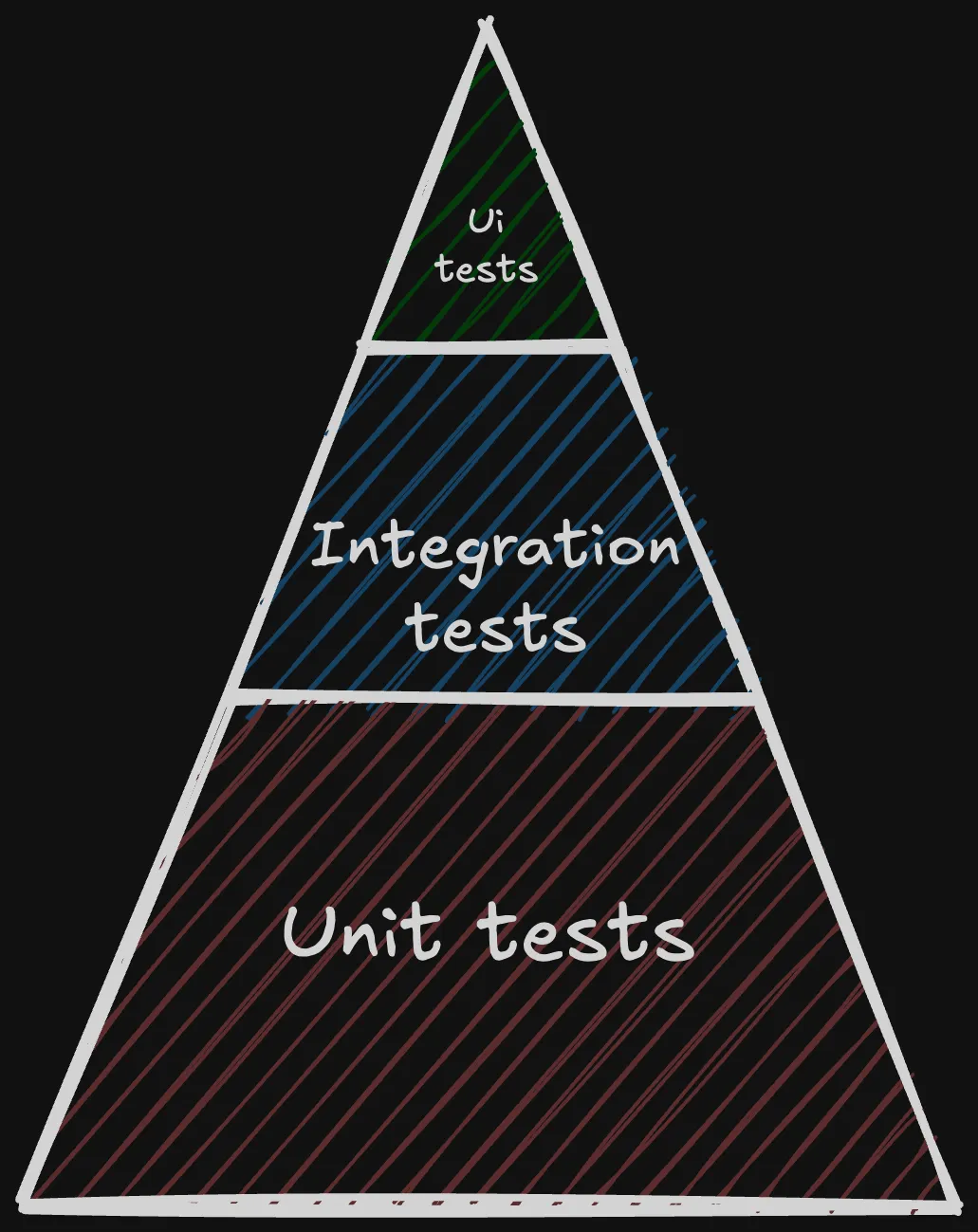
Soulignant la fragilité des tests UI (si l’UI change, le test est obsolète), cette stratégie mise la plupart des efforts sur les tests unitaires afin d’assurer que le core de l’application est protégé par la batterie de test.
Malheureusement, certaines applications continuent de renverser cette pyramide pour finir par donner naissance au software testing ice-cream cone :
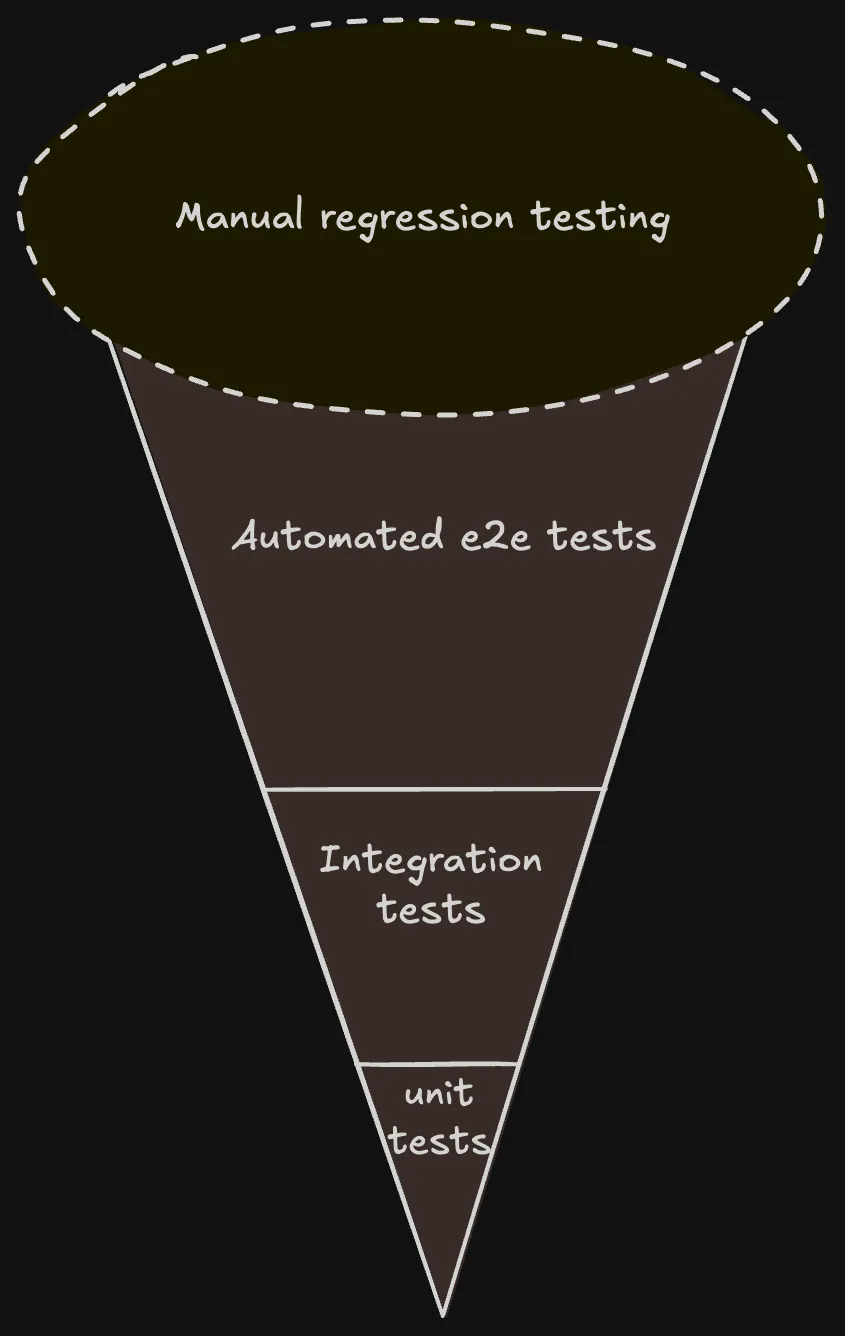
Dans cette situation, les tests de régression manuels sont nombreux, soumis aux variables humaines (erreur, imprécision, omission, lenteur) et bien souvent les tests fonctionnels automatisés (e2e) trop nombreux, lents et fragiles. La part des tests unitaires est réduite à peau de chagrin.
Cet anti-pattern se manifeste dans les codebases où la condition pour appliquer la pyramide de test n’est pas remplie : un code suffisamment découpé pour obtenir des tests unitaires pertinents et utiles.
Une stratégie plus , popularisée sous la forme du Testing Trophy de Kent C. Dodds, est le testing diamond :
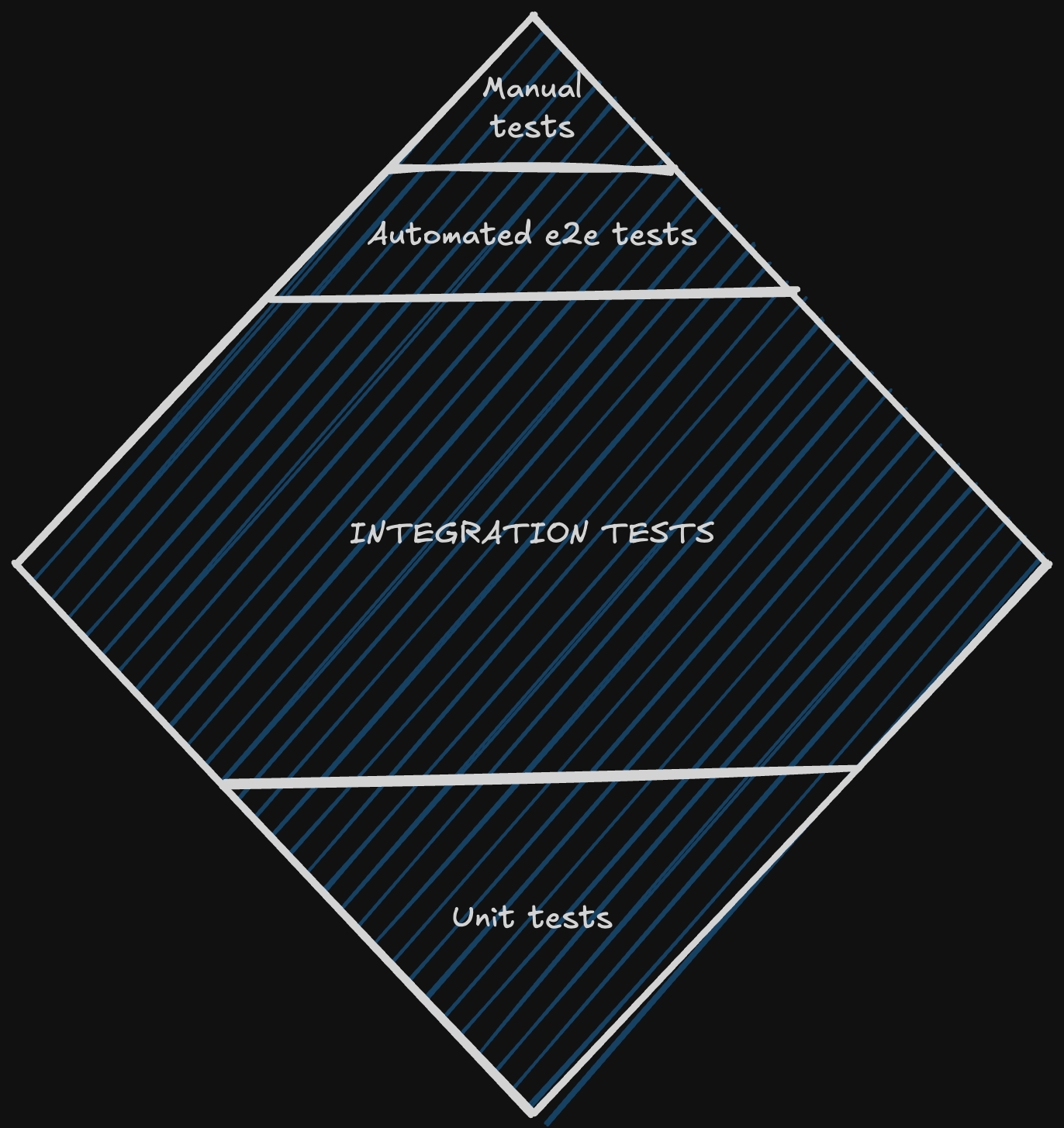
Avec le testing diamond, la confiance générée par les tests provient principalement des tests d’intégration (scope le plus large) auxquels s’ajoute le test du cœur critique de l’application (tests unitaires) et du happy flow ou smoke testing via des tests e2e automatisés ou des scripts manuels pour les scripts tiers.
Tester c’est douter ? Tester c’est cueillir un champignon
Étant donné l’état de la codebase et les délais du projet sur lequel est intervenue Kate Marshalkina, aucune de ces stratégies ne pouvait s’appliquer. Il a donc fallu établir une stratégie davantage personnalisée pour parvenir à une barrière de tests utile et maintenable : le testing mushroom.
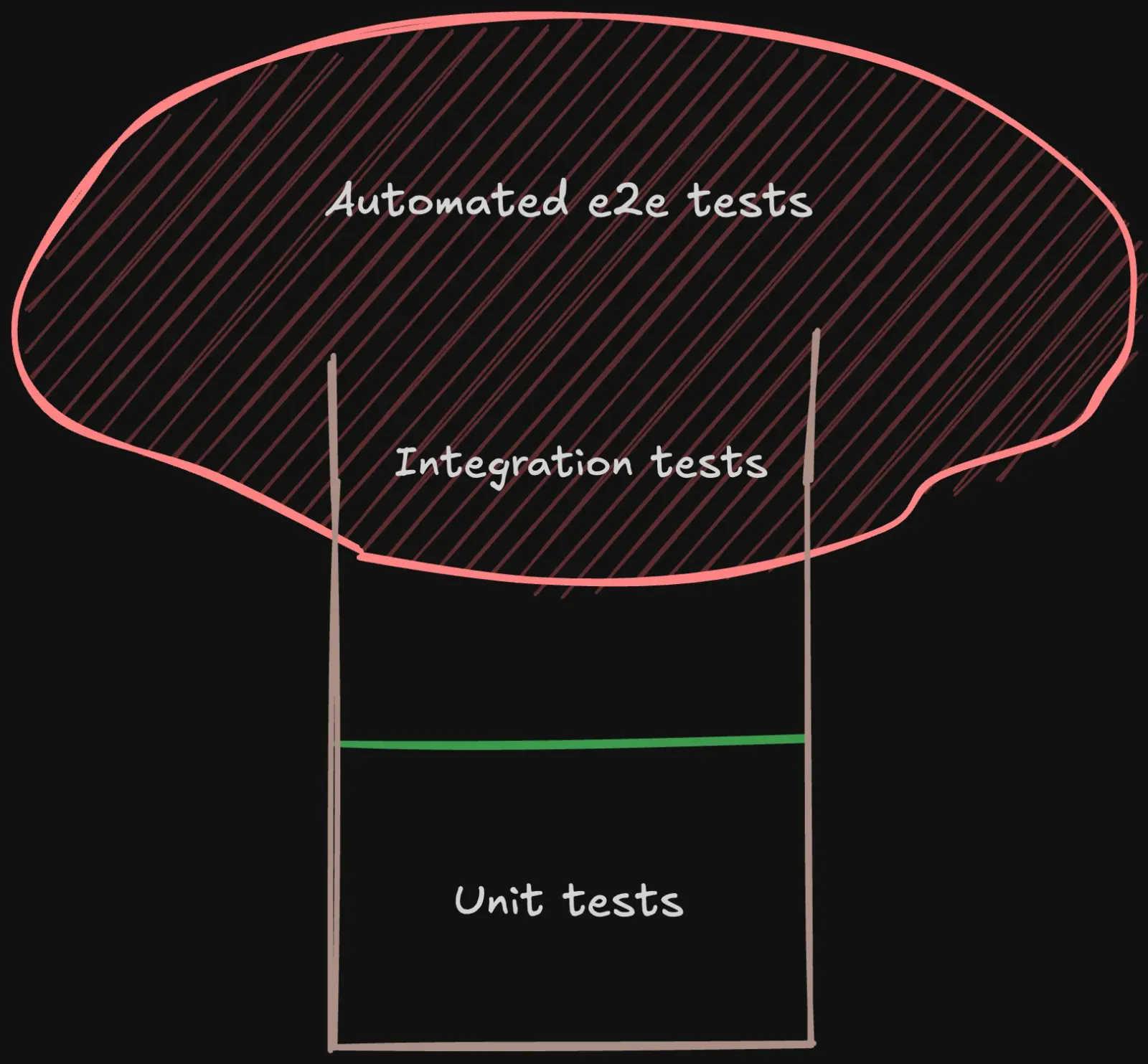
Au premier abord, cette stratégie semble identique à l’anti-pattern de l’ice-cream cone mais la différence se situe principalement dans l’imbrication des tests d’intégration, difficiles ou peu utiles dans le cadre d’un frontend, avec les tests e2e.
Il y a quelques années encore les tests snapshot de composants étaient courants et occasionnaient une perte de temps et un grand nombre de faux-positifs. Ce temps perdu est réinjecté dans une plus grande attention portée à la solidité et pertinence des tests e2e. En effet, l’avantage de cette stratégie est que, loin d’être une panacée, elle est un compromis entre toutes les stratégies historiques, adaptée à un contexte particulier et s’appuyant sur le fait qu’aujourd’hui les tests fonctionnels automatisés en manipulant l’UI ne sont plus difficiles et coûteux… à condition de les exécuter correctement.
La performance des tests e2e
Ne crions pas victoire trop vite car la performance des tests e2e est encore un problème. La trop longue durée des pipelines, la mauvaise conception des scénarios, leur multiplication et la fragilité des tests demeure fréquentes.
Ainsi, Kate Marshalkina termine son talk en présentant les bonnes pratiques que son équipe et elle ont appliqué afin de rendre les tests e2e écrits avec Playwright performants, rapides, utiles et lisibles par tous :
- https://github.com/vitalest/playwright-network-cache pour consommer depuis un cache local les appels API similaires exécutés dans les tests précédents, d’où l’inclusion des tests intégrations dans la partie E2E (le chapeau du champignon). Tout comme la mushroom strategy elle-même, c’est un trade-off entre des tests e2e demandant de maintenir de fastidieux mocks d’API au risque de se retrouver avec de faux-positifs et de ne pas capturer de vrais bugs et ceux attaquant directement l’API.
eslint-plugin-playwrightpour corriger les mauvaises pratiques- utilisation du Page Object Model et du décorateur
@step()pour exposer de manière claire les actions possible sur une page et grouper les actions haut niveau de l’utilisateur En combinaison avec Allure, les tests E2E, leurs résultats et leurs itérations sont compréhensibles pour les individus non techniques de l’équipe - lancement en parallèle des tests et augmentation du nombre de workers
Remixer Remix
Dans cette conférence, Antoine Chalifour nous fait part de ce qui l’a poussé à s’éloigner des opinions de Remix afin de modeler le framework selon ses besoins, celui de son produit Geckosocial.
Le projet d’Antoine permet de gérer ses publications de manière automatisée sur LinkedIn et d'autres plateformes. Il est composé d’un éditeur de texte, d’une fonctionnalité de mentions d'utilisateurs, d’une vue calendrier, de capacités d'édition de texte enrichi et d’une intégration d'IA.
Ok mais… c’est quoi déjà Remix ?
Remix c’est un méta-framework React web full-stack particulièrement puissant et offrant un ensemble de fonctionnalités côté serveur solides. Une des particularités de Remix est qu’il couple fortement le routage et la récupération de données, ce qui peut influencer la manière dont il est utilisé dans un projet.
Qu’est ce qui a mené à « utiliser Remix de la mauvaise manière » ?

1. Limitations du Rendu Côté Serveur
Certains composants comme ceux avec rendu de date rendent difficile l’utilisation du SSR. De plus, l'éditeur de texte enrichi utilisant Lexical a besoin des nœuds DOM et fonctionne uniquement côté client. Ainsi, le SSR a été désactivé pour l'expérience utilisateur connecté.
2. Données Non Plus Couplées aux Routes
Les données non plus couplées aux routes sont un autre facteur qui a contribué à l'utilisation inappropriée de Remix dans le cas d’Antoine.
Les exigences de données sont devenues plus complexes pour chaque écran, et les données sont réutilisées entre les composants qui ne correspondent pas aux routes. De plus, certains dialog nécessitent des données asynchrones mais ne sont pas liés à des routes spécifiques. Cela a rendu la revalidation coûteuse car les routes parentes chargeaient trop de données
3. Formulaires Complexes
Enfin, les formulaires complexes sont également à l’origine de l'utilisation détournée de Remix.
Au fil du projet, les formulaires ont évolué au-delà de simples entrées, demandant une validation conditionnelle. Il a fallu également compter avec les difficultés liées aux tableaux d'objets dans les formulaires et aux actions n’étant pas toujours déclenchées par des boutons de soumission.
Est-ce que Remix a encore sa place dans sa stack techno, est-ce toujours utile ?
Sa réponse est un grand OUI ! Remix fournit une excellente DX (developer experience) grâce à Vite, incluant la mise en page et le routing imbriqué, le rendu côté serveur (SSR) avec amélioration progressive pour des pages spécifiques, des redirections d'authentification côté serveur ainsi que l'intégration avec des serveurs Node existants.
Les points clés a retenir de son talk ?

- Les frameworks ne sont que des outils : rien n’oblige à utiliser toutes ses fonctionnalités (👉 edge middleware)
- Migrer progressivement pour ne pas tout réécrire d’un coup
- Continuer à déployer en production pendant la migration
- Utiliser ce qui fonctionne pour les besoins spécifiques du produit – amen
En résumé, Antoine a proposé un excellent talk montrant que la tech est au service des développeurs et non l’inverse !
Un mathématicien et un développeur entrent dans un foo bar…
From Chaos to Clarity: Mathematical Foundations for Maintainable React Applications
Cette conférence étonnante d’Héla Ben Khalfallah porte sur la façon d'optimiser une codebase React grâce à un trio de concepts mathématiques :
- la théorie des graphes
- la théorie des catégories
- lambda-calculus
L’objectif derrière ces concepts intimidants est clair : produire du code robuste et performant.
Théorie des graphes : visualiser et structurer notre code react
Même si l'idée de représenter une application comme un graph est familière, Héla rappelle les caractéristiques nécessaires du graph afin que la représentation soit pertinente :
- modéliser les fichiers comme des nœuds et les imports comme des arêtes pour repérer immédiatement les dépendances circulaires pouvant perturber la maintenance et le bundling
- identifier les communities : les algorithmes de community detection (e.g. Louvain) montrent comment regrouper les fichiers pour maximiser la cohésion interne et minimiser les dépendances extérieures. C'est un outil objectif pour organiser les dossiers et les packages de manière optimale.
- mesurer l'influence de chaque fichier : les métriques comme la centrality, la density ou le sparsing permettent de repérer rapidement les zones à réfactoriser, les fichiers critiques à tester en priorité et les morceaux de code spaghetti pénalisant l'évolution du projet
Catégorie théorie ou comment revenir à des fonctions pures et des transformations unifiées
Et une petite plongée dans la théorie des catégories pour la conception fonctionnelle en compagnie d’Héla. L'objectif est de passer des mutations et des effets secondaires aux transformations. Quelques principes :
- préférer le morphisme à la mutation : au lieu de muter les données, appliquer une suite de transformations qui maintiendra la structure de départ et minimisera les effets de bord
- Functors et Monads. Concrètement, en JavaScript, les
Arrays sont naturellement des functors via le.map, tandis que les structures commePromisefonctionnent comme des monades via le.then. Ces concepts rappellent simplement à quel point découper son code en transformations pures peut simplifier les tests et la lisibilité. Ou encore neverthrow qui est un package npm qui propose une MonadResulti.e la meilleure manière de gérer un résultat qui peut être en erreur 😎_._ - Transducers
L'optimisation de
map,filteretreduceen une seule itération, sans créer d'intermédiaire superflu, reste un incontournable pour les ensembles de données volumineux. Concrètement, faire un.filtersuivi d’un.mappuis d’un.reduce, même si la complexité algorithmique reste la même (potentiellementO(n)), sur un gros volume de données, il peut être intéressant de les regrouper afin d’éviter 2 tours de boucle superflus.
On voit ici à quel point les bonnes pratiques côté code s’inspirent de la théorie des catégories et traduisent ses principes… comme le montre parfaitement la composition !
Lambda calculus : optimiser grâce à la composition et aux lazy evaluations
Le Lambda calculus fournit un éventail d’outils qui sont déjà bien connus des développeurs :
- le currying pour transformer les fonctions à multiples arguments en une chaîne de fonctions à un seul argument. Loin d’être accessoire ou superficiel, c'est un moyen efficace de réutiliser les sous-ensemble d’une logique
- les Higer-Order Functions (HOFs), importantes pour la composition, par exemple d’un debounce et d’un throttle. Mieux on segmente les responsabilités dans nos HOFs, plus c'est réutilisable et clair
- lazy evaluation et memoization : deux grands classiques ! D’une part n'évaluer que ce dont on a besoin quand on en a besoin, d’autre part conserver le résultat pour éviter de répéter des opérations coûteuses
- le pattern du trampoline pour gérer la récursivité en JavaScript sans causer de stack overflow. L’idée du trampoline est de retourner une fonction exécutée par le trampoline (appelée continuation) plutôt que d’ajouter sempiternellement un niveau à la stack jusqu’à l’overflow_._ C’est le trampoline, la fonction wrapper, qui se charge d’appeler la fonction récursive à la fin de son traitement plutôt que la fonction récursive qui s’appelle elle-même. C’est un pattern indispensable dans un contexte de code récursif puisqu’à date JavaScript ne supporte malheureusement pas les Tail Recursive Functions.
Pourquoi ce talk est un précieux rappel ?
Toutes ces bonnes pratiques pour un code robuste ne devraient pas être surprenantes pour beaucoup de développeurs. Mais cette conférence est la bienvenue car de la théorie à la pratique il y a parfois un abysse. Même en tant que développeur senior, la tentation de laisser s'installer quelques entorses à la pureté des fonctions est fréquente.
Héla a donc rappelé de manière concise et claire pourquoi ces outils et techniques sont utiles :
- Une meilleure maintenabilité : des fonctions pures et un code bien modulaire se manipulent et se refactorisent plus facilement
- Une plus grande performance : la lazy evaluation, la bonne organisation des imports et l’utilisation des outils de la théorie des catégories (morphisme, functors et monads, transducers) afin d’éviter les side-effects peuvent se révéler réellement determinants pour un projet React ou front de grande envergure
Ces techniques sont déjà au cœur de la plupart des bonnes pratiques et les voir présentées ensemble dans un format clair et méthodique est un rappel utile pour garder un projet propre et évolutif.
Bref, un indispensable à intégrer ou réintégrer dans les équipes souhaitant maintenir un standard de qualité élevé sur leurs applications React.
Les autres conférences
C’est tout pour nous cette année, n’hésitez pas à consulter sur YouTube ces conférences et les autres pour ne pas manquer notamment :
- le cours d’histoire de Kent C. Dodds “des origines obscures et un peu sales du web aux RSC” (nom non officiel) ;
- A Tale of Two Components: Mastering A/B Testing in React de Violina Popova sur sujet un peu niche mais pointu et brillamment exposé ;
- la petite leçon de bon sens de TkDodo avec React Query API Design - Lessons Learned qui, sans être hélas très surprenante, offre quelques retours d’expérience sur la difficulté de humaine et technique de produire du code pour l’Open Source.
À propos des auteurs

Articles connexes




Veille craft, cloud & archi
Le meilleur de nos articles, une fois par mois.
Je m'abonneDésabonnement en 1 clic. Pas de partage de données.
Cet article vous a inspiré ?
Vous avez des questions ou des défis techniques suite à cet article ? Nos experts sont là pour vous aider à trouver des solutions concrètes à vos problématiques.