Docker, volumes et perte de données : pourquoi vos données “disparaissent”

Relu par : Michaël Bernasinski | Emmanuelle Gouvart
Récemment, j’ai vécu ma première “vraie” perte de données dans mon homelab. Rien de critique… mais suffisamment frustrant pour me rappeler une règle essentielle avec Docker : 👉 Les données ne disparaissent presque jamais. On ne regarde juste pas au bon endroit.
Le contexte : Calibre-Web dans mon cluster Docker Swarm
Pour gérer ma bibliothèque d'ebooks, j'ai déployé Calibre-Web sur mon cluster Docker Swarm.
Tout fonctionnait parfaitement : j'uploadais des livres, je les lisais depuis n'importe quel appareil… bref, tout roulait. Quelques jours plus tard, je modifié ma stack et… catastrophe : plus aucun livre. Tout a disparu. 😱
Le plus étrange ? La configuration de Calibre-Web était toujours là. Comment était-ce possible ?
Comprendre comment Docker gère les données
Avant de comprendre le problème, il faut rappeler un point fondamental :
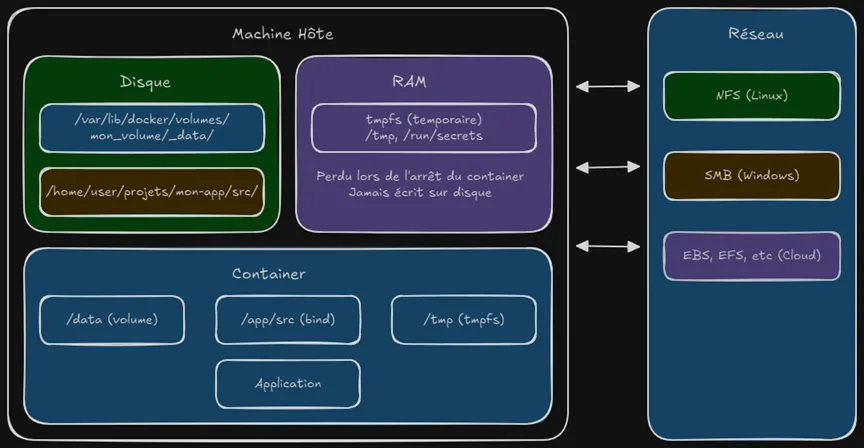
Par défaut, un conteneur Docker est éphémère
- Les fichiers sont stockés dans le conteneur
- Si le conteneur est supprimé → les données disparaissent
Pour éviter ça, on utilise :
- des volumes Docker
- des bind mounts
- ou des stockages distants (NFS, etc.)
👉 Mais Docker ne fait aucune magie :
Il ne sait pas quels fichiers sont importants.
L'origine du problème
Après investigation, j'ai identifié la cause :
- J'avais mal lu la documentation du conteneur
- J’avais monté un volume sur un mauvais chemin
- Et surtout : ce chemin n’était pas utilisé par l’application
Lors de la recréation du conteneur, Docker a fait exactement ce qu’il est censé faire : 👉 Créer automatiquement un nouveau volume vide
Résultat :
- mon application lisait un dossier vide
- mes données existaient toujours… mais dans un autre volume
Une erreur très courante avec Docker
L’erreur que j’ai commise est en réalité assez fréquente avec Docker : monter un volume sur un mauvais chemin, ou sur un répertoire qui n’est tout simplement pas utilisé par l’application.
Dans ce type de situation, le comportement de Docker peut être trompeur. Le conteneur démarre sans problème, aucune erreur n’est remontée, et tout semble fonctionner normalement. Pourtant, les données ne sont pas écrites à l’endroit attendu.
En pratique, cela signifie que la persistance est silencieusement cassée : les fichiers sont stockés ailleurs, voire dans un volume éphémère, sans que cela ne soit immédiatement visible.
Schéma : ce qu’il s’est vraiment passé
Pour comprendre visuellement :
👉 C’est exactement ce qui rend ce problème piégeux.
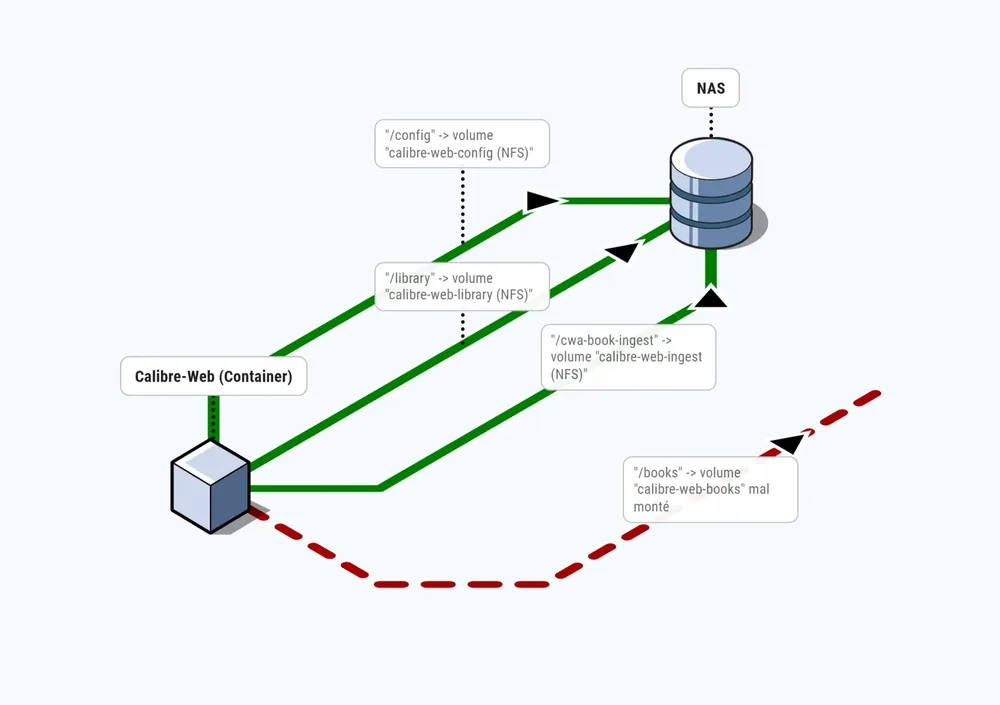
👉 La clé à comprendre : Docker ne “perd” pas les données. Il les écrit simplement ailleurs que là où l’application les lit.
La configuration corrigée
Voici la stack Compose fonctionnelle :
services:
calibre-web-automated:
image: crocodilestick/calibre-web-automated:v4.0.6
networks:
- proxy
volumes:
- calibre-web-config:/config
- calibre-web-library:/calibre-library
- calibre-web-ingest:/cwa-book-ingest
- /etc/localtime:/etc/localtime:ro
environment:
- PUID=1000
- PGID=1000
- TZ=Europe/Paris
- DOCKER_MODS=linuxserver/mods:universal-calibre
deploy:
mode: replicated
replicas: 1
networks:
proxy:
external: true
volumes:
calibre-web-config:
driver: local
driver_opts:
type: nfs
o: addr=192.168.0.174,nolock,soft,rw
device:":/volume1/docker-swarm-nfs/calibre-web/config"
calibre-web-library:
driver: local
driver_opts:
type: nfs
o: addr=192.168.0.174,nolock,soft,rw
device:":/volume1/docker-swarm-nfs/calibre-web/library"
calibre-web-ingest:
driver: local
driver_opts:
type: nfs
o: addr=192.168.0.174,nolock,soft,rw
device:":/volume1/docker-swarm-nfs/calibre-web/ingest"
Cette fois, tous les répertoires utilisés par l’application sont correctement persistés.
Comment tester la persistance d’un service
Une bonne pratique simple (et souvent oubliée) :
- Démarrer le service
- Ajouter une donnée (ex : un fichier ou un livre en l'occurrence)
- Supprimer le conteneur
- Le recréer
- Vérifier que la donnée est toujours présente et accessible
👉 Si ce test échoue, votre persistance est cassée.
Ce que j'ai appris
Cette expérience m’a appris une chose essentielle : 👉 Avec Docker, une donnée n’est persistante que si vous savez exactement où elle est écrite.
Les volumes ne sont pas compliqués… mais ils sont implicites :
- Docker ne valide pas votre intention
- Il exécute simplement votre configuration
Résultat : une simple erreur de mapping peut donner l’impression que les données ont disparu, alors qu’elles sont juste… ailleurs.
Conclusion
Docker est un outil extrêmement puissant, mais aussi très permissif. Et c’est justement ça le danger.
En pratique, ce qu’il faut retenir :
- Identifiez toujours les dossiers critiques d’une application
- Vérifiez où les données sont réellement écrites
- Testez systématiquement vos déploiements
- Et surtout : ne faites jamais confiance à une configuration non testée
Parce qu’en production, ce type d’erreur ne pardonne pas.
À propos de l'auteur

Articles connexes
Connecter Datadog à un réseau 100% hors-ligne : retour d'expérience avec Vector
31 mars 2026

Souveraineté & éco-conception : notre REX DevLille 2026 (Pt 2)
8 juillet 2026

DORA Metrics x Datadog : Piloter sa vélocité sans effort
19 mars 2026

Le Manifeste du Platform Craftsmanship : L'engagement HoppR
3 février 2026
Veille craft, cloud & archi
Le meilleur de nos articles, une fois par mois.
Je m'abonneDésabonnement en 1 clic. Pas de partage de données.
Cet article vous a inspiré ?
Vous avez des questions ou des défis techniques suite à cet article ? Nos experts sont là pour vous aider à trouver des solutions concrètes à vos problématiques.