Clean Architecture avec React : remettre des frontières dans un frontend qui grandit
Écrit par : Paul Plancq
Relu par : Edouard Cattez | Pierre-Emmanuel Denys | Michaël Bernasinski | Maxime Deroullers | Emmanuelle Gouvart
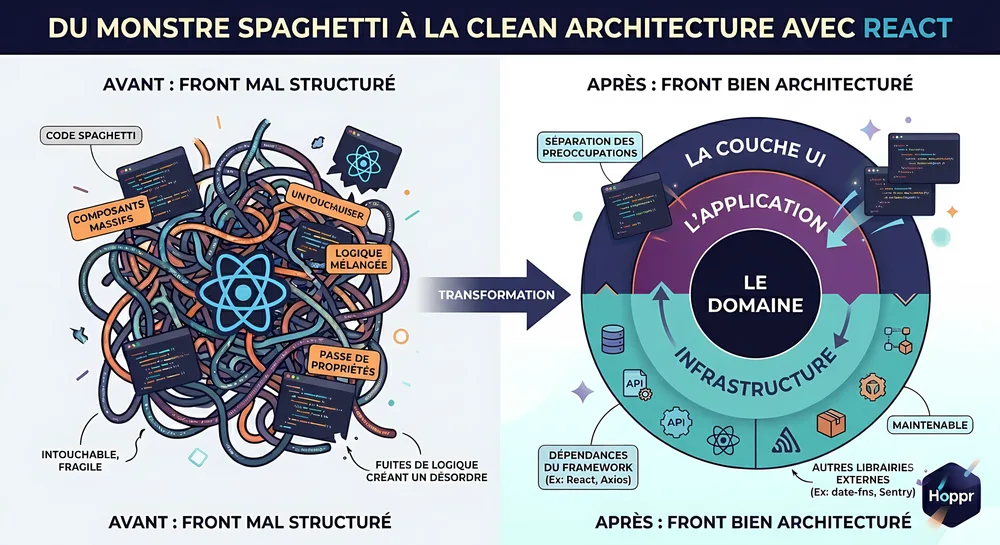
Avez-vous déjà vu un frontend React devenir un monstre difficile à dompter ?
J’ai été amené à travailler sur plusieurs projets de refonte du frontend, et tous avaient le même problème.
Un composant affiche une liste, va chercher la donnée, valide un formulaire, applique une règle métier, appelle une API, gère un toast… puis on lui ajoute encore un useEffect pour que tout tienne.
Au début, tout cela paraît supportable. Et puis, à mesure que le produit grandit, le frontend devient difficile à maintenir et à faire évoluer. Pas parce que React serait “mauvais”. Pas parce que l’équipe serait moins bonne. Pas parce que le code serait généré par une IA. Mais parce que les responsabilités ont fini par se mélanger.
C’est ce constat qui m’a poussé à lancer un lab open source autour de la Clean Architecture appliquée au frontend. Je voulais répondre à une question simple : comment garder des frontières claires dans un frontend qui devient complexe et chargé de responsabilités métier ?
Pour creuser le sujet, je suis parti d’un cas réel : un frontend avec de l’offline, de la persistance, des règles métier et des décisions d’architecture lourdes.
Avant d’entrer dans le lab : de quoi parle-t-on exactement ?
Clean Architecture, SOLID et DDD (Domain Driven Design). On les cite souvent ensemble, mais ils ne désignent pas exactement la même chose.
Et si le sujet t’intéresse, chez HoppR on propose une formation dédiée au DDD pour poser des bases solides avant d’aller plus loin. Formation DDD HoppR
La Clean Architecture parle surtout de la structure globale du système. L’idée centrale est que le cœur métier doit rester protégé des détails techniques. Une règle métier ne devrait pas dépendre de React, d’API, d’un routeur ou d’un framework de DI. En pratique, cela pousse à organiser le code en couches et à faire entrer les dépendances vers le centre, pas l’inverse.
Les principes SOLID, eux, agissent à une autre échelle. Ils aident à mieux découper les composants, modules et les responsabilités :
- Single Responsibility Principle : un composant React n’a pas à faire en même temps rendu, orchestration, validation métier et persistance ;
- Open/Closed Principle : si je change la stratégie de stockage, je préfère ajouter une implémentation plutôt que réécrire le cœur métier ;
- Dependency Inversion Principle : le métier dépend de contrats, pas directement d’implémentation d’objet.
Et puis il y a le DDD. Là encore, l’idée n’est pas de “faire du DDD pour faire du DDD”, mais de remettre le métier au centre. Cela passe par plusieurs choses très concrètes : nommer le code avec le vocabulaire du domaine, faire émerger des bounded contexts clairs comme collection, wishlist ou maintenance, et enrichir le modèle avec de vraies notions métier comme des entités, des value objects et des règles explicites.
Dans le fond, ces trois approches se complètent très bien :
- la Clean Architecture aide à poser les frontières ;
- SOLID aide à mieux découper les responsabilités ;
- le DDD aide à mieux modéliser le métier.
Le lab n’applique donc pas une seule recette. Il combine ces approches pour répondre à un problème très concret de frontend : garder un code qui reste compréhensible quand le produit grossit.
Les couches : qu’est-ce qu’on met dans domain, application, infrastructure et ui ?
Avant de parler du choix des vertical slices, il me paraît utile de poser clairement le rôle de chaque couche. Parce qu’on voit souvent ces mots passer dans des schémas, sans vraiment expliquer ce qu’ils contiennent.
Dans mon lab, je raisonne de cette manière :
| Couche | Rôle | Exemples dans le lab |
|---|---|---|
| domain | le cœur métier, ses invariants et ses contrats | entités, value objects comme GameTitle , interfaces de repository |
| application | l’orchestration des actions métier | use cases comme AddGameUseCase , EditGameUseCase , stores |
| infrastructure | les implémentations techniques concrètes | IndexedDBGameRepository , mappers, wiring DI |
| ui | l’affichage et les interactions React | pages, composants, hooks, formulaires |
Le point important n’est pas seulement de nommer ces couches. Le point important, c’est la direction des dépendances :
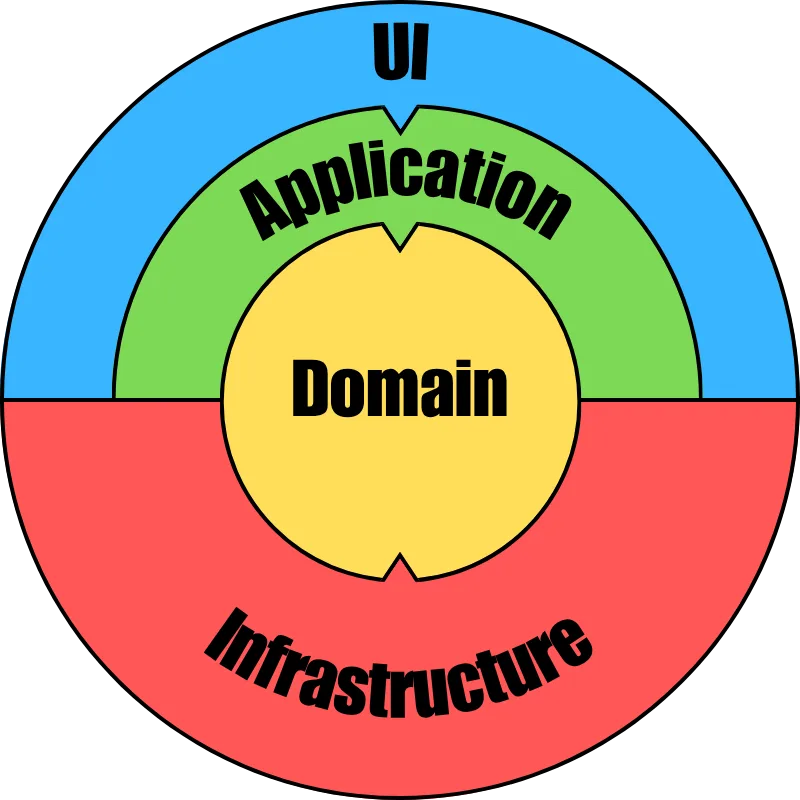
Autrement dit :
- l’
uipeut appeler l’applicationou ledomain; - l’
applicationpeut manipuler ledomain; - l’
infrastructureimplémente les contrats définis dans ledomain; - mais le domain reste hermétique à la technique : il ne connaît que les règles métier, jamais React, l’API ou les librairies.
C’est cela, au fond, que je cherche quand je parle de frontières. Je veux pouvoir lire une classe du domain sans tomber sur un détail de framework. Je veux que l’application orchestre sans se soucier de la manière dont la donnée est stockée. Et je veux que l’ui projette l’état sans devenir l’endroit où toute la logique finit par s’accumuler.
Pourquoi cette approche m’a intéressé côté frontend
Ce que le backend sait déjà assez bien faire, le frontend l’accepte encore trop souvent comme une fatalité : mélange des responsabilités, logique métier remontée dans l’interface, détails techniques diffusés un peu partout, difficulté à tester autrement qu’en montant toute l’application.
Ce n’est pas forcément visible au début. Sur un écran simple, tout peut paraître raisonnable. Mais dès qu’un projet s’installe dans la durée, ajoute du offline-first, des règles métier un peu sérieuses et plusieurs flux utilisateurs, ce manque de frontières finit par coûter très cher.
Le problème n’est pas React, c’est l’absence de frontières
Pendant longtemps, on a accepté côté frontend des choses qu’on refuserait immédiatement côté backend :
- de la logique métier dans des composants ;
- des détails techniques qui remontent partout ;
- des erreurs gérées de manière implicite ;
- une structure de projet pensée pour ranger les fichiers, pas pour absorber le changement.
Quand j’entends “c’est le front, c’est normal que ce soit un peu le bazar”, j’ai toujours du mal avec cette idée. Sur des applications simples, oui, on peut très bien vivre avec une structure légère. Mais dès qu’un produit dure, accumule des règles, de la dette, plusieurs écrans, du offline-first ou des synchronisations plus complexes, le sujet n’est plus la taille des composants. Le sujet devient l’architecture du changement.
La Clean Architecture m’a intéressé pour cette raison précise : elle force à répondre à une question simple mais redoutablement utile :
Qui a le droit de parler à qui ?
Première décision : raisonner par contexte métier, pas par type de fichier
Le premier piège, sur un front React, c’est de confondre plan de classement et architecture.
Une arborescence de ce type n’est pas absurde :
src/
├── components/
├── hooks/
├── pages/
├── services/
└── api/
Le problème, c’est qu’elle répond surtout à la question : “quel genre de fichier est-ce ?”
Or, dans un projet qui grandit, la vraie question devient plutôt :
À quel besoin métier appartient ce changement ?
Dans le lab, j’ai donc choisi une structure en vertical slices : un dossier par contexte métier, et à l’intérieur de chaque contexte, les couches classiques de la Clean Architecture.
collection/
├── domain/
├── application/
├── infrastructure/
└── ui/
Concrètement, cela change beaucoup de choses.
Quand je travaille sur la collection de jeux, je reste dans collection/. Je n’ai pas besoin de traverser tout src/ pour recoller des morceaux répartis entre components, services, hooks et api. Le changement reste localisé, les dépendances sont plus lisibles, et l’ownership d’un contexte devient plus clair.
Ce choix ne réduit pas le nombre de fichiers. Il réduit surtout le coût mental pour comprendre où agir.
Une architecture n’est pas faite pour ranger les fichiers au jour 1. Elle est faite pour absorber le changement au jour 200.
Deuxième décision : remettre les règles métier dans le domaine
Une fois les frontières de dossiers clarifiées, il restait un problème plus profond : où vivent les règles métier ?
Au début, comme souvent, on part avec des types composés de primitives :
type Game = {
id: string;
title: string;
platform: string;
status: string;
};
C’est propre, court, très TypeScript-compatible. Mais ce n’est pas du métier. Une string vide reste une string valide pour le compilateur. Une typo dans un statut aussi.
Dans le lab, j’ai commencé à déplacer ces règles dans des value objects. Par exemple pour le titre d’un jeu avec GameTitle :
export class GameTitle {
private readonly value: string;
private constructor(value: string) {
this.value = value;
}
static create(value: string): Result<GameTitle, GameTitleError> {
const trimmedValue = value.trim();
if (trimmedValue.length === 0) {
return Result.err({
field: 'title',
message: 'Game title cannot be empty',
});
}
if (trimmedValue.length > 200) {
return Result.err({
field: 'title',
message: 'Game title cannot exceed 200 characters',
});
}
return Result.ok(new GameTitle(trimmedValue));
}
}
Ce n’est pas spectaculaire. Mais c’est un changement de gravité important.
La règle ne vit plus dans un formulaire React, ni dans un use case, ni dans un if perdu quelque part dans l’ui. Elle vit là où elle devrait toujours vivre : dans le domain.
Le bénéfice est double :
- il devient impossible de créer un
GameTitleinvalide sans le savoir ; - les tests deviennent triviaux, car ils ne dépendent ni du navigateur, ni du DOM, ni d’un composant.
Et c’est aussi un vrai changement de stratégie de test : on passe de tests de composants lourds (DOM + mocks d’API + orchestration UI) à des tests unitaires de logique pure, rapides, robustes et beaucoup plus ciblés.
À ce moment-là, le domaine commence réellement à porter le métier au lieu d’être un simple amas de types.
Troisième décision : faire de React un client de l’application
C’est probablement le point le plus délicat quand on essaie d’appliquer la Clean Architecture côté frontend.
Sur le papier, tout va bien : le domaine contient les règles, les use cases orchestrent, l’infrastructure implémente. Mais au moment de brancher cela à React, une question revient immédiatement :
Si mon use case ne connaît pas React, comment l’
uisait-elle qu’elle doit se re-render ?
Ma réponse, dans ce lab, a été d’introduire un store applicatif. Pas un mini-framework maison. Pas un Redux déguisé. Un objet dont le rôle est simple : orchestrer les use cases, exposer un état lisible par l’ui et notifier les abonnés, via le pattern observable, quand cet état change.
Concrètement, le composant React ne déclenche pas directement un use case : il parle au store. Le store, lui, coordonne les use cases et met à jour son snapshot. C’est cette nuance qui me permet de garder l’ui la plus fine possible, sans déplacer l’orchestration dans les composants.
Le hook de l’ui qui s’y branche repose sur useSyncExternalStore :
export const useGamesSelector = <T>(selector: (store: GamesStoreInterface) => T): T => {
const store = useService<GamesStoreInterface>(COLLECTION_SERVICES.GamesStore);
const selectorRef = useRef(selector);
selectorRef.current = selector;
return useSyncExternalStore(
useCallback(cb => store.subscribe(cb), [store]),
useCallback(() => selectorRef.current(store), [store]),
);
};
Côté composant React, l’usage devient alors extrêmement simple et transparent :
const { games, isLoading } = useGamesSelector(state => state.getGamesList());
Si on ne connaît pas bien ce hook, l’idée peut paraître un peu abstraite. useSyncExternalStore est le mécanisme fourni par React pour s’abonner proprement à une source d’état externe au composant. Autrement dit, au lieu de bricoler un useEffect pour synchroniser un état local avec une autre source de vérité, on dit explicitement à React : “abonne-toi à cet objet, et re-rends quand son snapshot change”.
Dans le cas du lab, ce choix a eu un vrai effet de clarification.
Le store devient le point de jonction entre le cœur de l’application et React. Le composant, lui, ne porte plus l’orchestration. Il lit un snapshot, déclenche une action, et se contente de projeter l’état courant.
Dans GamesStore, j’ai même poussé l’idée un cran plus loin : les fetchs sont auto-déclenchés lors de la première lecture, ce qui évite de disperser du code d’orchestration dans les composants.
getGamesList(): GamesListState {
if (!this.hasFetchedList) {
this.hasFetchedList = true;
this.listIsLoading = true;
this.listSnapshot = { games: [], isLoading: true, hasError: false, error: null };
queueMicrotask(() => {
this.fetchGames();
});
}
return this.listSnapshot;
}
Autrement dit :
- le use case exécute.
- le store synchronise.
- React observe.
Pour moi, c’est là qu’on cesse d’essayer de “faire rentrer React dans la Clean Architecture”. On commence au contraire à voir React comme un client de l’application.
Quatrième décision : garder les détails techniques à leur place
Une architecture devient vraiment intéressante quand elle résiste aux détails techniques au lieu de se laisser piloter par eux.
Dans ce projet, un de ces détails est très concret : IndexedDB, parce que l’application a une ambition offline-first.
La solution la plus simple aurait été d’appeler IndexedDB directement depuis les composants ou d’injecter l’API navigateur dans des objets métier. Techniquement, ça fonctionne. Architecturalement, c’est une très mauvaise idée.
J’ai donc gardé un contrat dans le domaine et une implémentation dans l’infrastructure. Le repository IndexedDB convertit les DTOs, interagit avec le navigateur et renvoie des Result explicites.
export class IndexedDBGameRepository implements GameRepositoryInterface {
constructor(private readonly dbService: IndexedDBInterface) {}
async save(game: Game): Promise<Result<void, RepositoryErrorInterface>> {
try {
const db = await this.dbService.getDatabase();
const dto = GameMapper.toDTO(game);
const transaction = db.transaction(this.dbService.getStoreName(), 'readwrite');
const store = transaction.objectStore(this.dbService.getStoreName());
const request = store.put(dto);
return await new Promise<Result<void, RepositoryErrorInterface>>((resolve, reject) => {
request.onsuccess = () => resolve(Result.ok(undefined));
request.onerror = () => reject(new SaveError(request.error));
transaction.onerror = () => reject(new SaveError(transaction.error));
});
} catch (error) {
return this.handleError(error);
}
}
}
Même logique pour la DI : j’utilise InversifyJS, mais je refuse d’infecter le domain avec des décorateurs. Toute la configuration vit dans le wiring, c’est-à-dire dans l’endroit où l’on branche explicitement les contrats et leurs implémentations concrètes :
options
.bind<GameRepositoryInterface>(COLLECTION_SERVICES.GameRepository)
.toDynamicValue(
services => new IndexedDBGameRepository(services.get<IndexedDBInterface>(COLLECTION_SERVICES.IndexedDB)),
)
.inSingletonScope();
Pourquoi tenir à ce point à ce wiring explicite ? Parce que si j’introduis des décorateurs InversifyJS directement dans le domain, le cœur du métier commence à connaître un détail d’infrastructure. Une entité ou un use case ne devrait pas savoir qu’un conteneur existe. Je préfère donc que tout ce qui concerne l’assemblage des objets reste confiné dans serviceCollection.ts, là où cette responsabilité a vraiment sa place.
Ce point est important, car on caricature souvent la Clean Architecture en frontend comme une couche “enterprise” importée du backend. Dans mon cas, la question n’était pas “est-ce que je veux faire sophistiqué ?”. La question était :
Comment garder mon domaine pur, testable et indépendant des choix de stockage ou du conteneur DI ?
La conséquence utile, c’est que certaines décisions restent différables. IndexedDB aujourd’hui, autre chose demain. ui brute aujourd’hui, ui raffinée demain. Le métier, lui, ne bouge pas au même rythme que les détails.
Le bonus caché : tester le métier à la vitesse de la lumière
L'un des gains les plus immédiats de cette approche se situe dans la suite de tests. En temps normal, tester une règle métier dans React implique souvent de :
- Charger un environnement DOM virtuel (
jsdomouhappydom). - Monter un composant avec
Testing Library. - Simuler des événements de saisie.
- Attendre les re-renders.
- Devoir mettre à jour des snapshots obsolètes.
C’est lent, et parfois fragile.
En déplaçant la logique dans le domaine via des Value Objects ou des Use Cases, le test devient une simple fonction pure. Plus besoin de simuler le navigateur : on teste du code TypeScript brut.
Le résultat ? Des tests qui s'exécutent en quelques millisecondes, sans aucune dépendance au framework.
describe('GameTitle', () => {
it('doit créer un titre valide', () => {
const result = GameTitle.create('The Legend of Zelda');
expect(result.isOk()).toBeTruthy();
expect(result.unwrap().value).toBe('The Legend of Zelda');
});
it('doit rejeter une chaîne vide avec une erreur explicite', () => {
const result = GameTitle.create('');
expect(result.isErr()).toBeTruthy();
expect(result.getError()).toEqual({
field: 'title',
message: 'Game title cannot be empty',
});
});
});
On ne teste plus "si le bouton affiche une erreur", on teste que "le système interdit l'existence d'un titre invalide". Cette nuance change tout : votre confiance dans le code ne dépend plus de la stabilité de votre UI, mais de la robustesse de votre modèle.
Les trade-offs que j’accepte volontairement
Évidemment, cette approche n’est pas gratuite.
Elle produit :
- plus de fichiers ;
- plus d’objets ;
- plus de câblage explicite ;
- plus de mappers/DTOs à écrire au départ ;
- un coût de lecture initial plus élevé pour quelqu’un qui découvre la clean architecture.
Je l’accepte parce que ce coût est payé une fois, là où le chaos se repaie à chaque évolution, à chaque bug, à chaque refactor, à chaque nouvelle feature.
Et surtout, cette approche m’oblige à être honnête sur mes décisions :
- si un objet connaît React, c’est qu’il n’est pas dans la bonne couche ;
- si un détail d’infrastructure remonte trop haut, on le voit vite ;
- si une règle métier est dispersée, elle devient immédiatement suspecte.
Autrement dit, l’architecture ne fait pas disparaître la complexité métier. Son rôle est plutôt de réduire l’entropie logicielle. Elle transforme une complexité technique diffuse et subie en une complexité métier explicite, localisée et donc enfin pilotable.
Ce que cette approche m’apporte réellement
Ce que j’aime dans ce lab, ce n’est pas d’empiler des patterns. C’est de voir qu’ils deviennent utiles ensemble :
- les vertical slices pour localiser le changement ;
- les value objects pour faire porter les invariants au domaine ;
- les stores applicatifs pour brancher React proprement ;
- les repositories pour isoler la persistance ;
- la DI manuelle pour garder le framework à sa place ;
- les ADRs pour documenter les choix avant qu’ils ne deviennent de la “magie historique”.
Aucune de ces décisions n’est très impressionnante seule. Ensemble, elles rendent le frontend plus lisible, plus testable et surtout plus stable quand le projet commence à durer.
Ce que cela change aussi pour l’équipe
Les bénéfices ne sont pas seulement techniques. Quand les frontières sont mieux posées, le travail d’équipe change aussi.
Pour quelqu’un qui rejoint le projet, l’onboarding devient plus simple : on comprend plus vite où chercher une règle métier, où se trouve l’orchestration et où vivent les détails techniques. Pour une équipe qui collabore à plusieurs, cela réduit aussi les zones grises. On discute plus facilement d’un sujet en disant “ça, c’est du domain” ou “ça, c’est un détail d’infrastructure”, au lieu de débattre dans un flou général.
Et pour les devs plus juniors ou celles et ceux qui découvrent ce type d’approche, je trouve que c’est aussi un bon support de montée en compétence. L’architecture ne fait pas le travail à leur place, mais elle rend beaucoup plus visibles les responsabilités de chaque morceau du système.
Conclusion
Je ne pense pas que tous les projets React aient besoin de Clean Architecture. Ce serait une autre forme de dogmatisme.
En revanche, je pense que beaucoup de projets peuvent déjà bénéficier de certains patterns issus de cette approche, même sans adopter toute la mécanique. Rien que le fait de mieux séparer la logique métier des composants, de centraliser l’orchestration dans un store ou d’empêcher les détails techniques de remonter partout peut déjà changer énormément de choses au quotidien.
La vraie question n’est donc pas seulement : “faut-il faire de la Clean Architecture dans React ?”
💡 Et ce n’est pas une question propre à React : ces principes restent valables quel que soit l’outil frontend, parce qu’ils relèvent d’abord de l’architecture, pas du framework.
Elle devient plutôt :
Quels principes me sont déjà utiles aujourd’hui, et à partir de quand le coût de l’absence de frontières dépasse-t-il le coût de leur mise en place ?
Et surtout, je pense qu’il ne faut pas attendre d’être sur un gros projet pour commencer à expérimenter ces approches. Au contraire, un petit projet est souvent le meilleur terrain pour apprendre. On a plus de place pour tester, se tromper, recommencer et comprendre vraiment ce que chaque choix architectural implique.
Parce qu’en général, quand un gros projet arrive, les deadlines arrivent avec. Et c’est rarement à ce moment-là qu’on apprend sereinement la Clean Architecture.
Dans mon cas, ce lab me sert justement à ça : documenter les bons choix, les compromis, les zones de friction, et surtout construire cette montée en compétence avant qu’elle ne devienne une nécessité sous pression.
Si le sujet t’intéresse, j’ai publié le code et les décisions d’architecture du projet ici :
- repo du lab : https://github.com/pplancq/lab-clean-architecture-react
- index des décisions : https://github.com/pplancq/lab-clean-architecture-react/blob/main/DECISIONS.md
Si tu veux challenger l’approche, t’en inspirer, ou simplement comparer avec ce que tu fais déjà en équipe, le plus simple est encore d’aller voir le lab, de parcourir les ADRs et de confronter cela à tes propres contraintes de terrain.
Car au final, dans un projet frontend, ce n’est pas React le centre de l’application mais le besoin métier.
À propos de l'auteur

Articles connexes

Effect, ou comment arrêter de découvrir ses erreurs en production
22 juin 2026

Du prototype à la prod : ce qu'on ne te dit pas sur la construction d'une solution IA solide
9 juin 2026

Platform Engineering : L’art de dompter l’entropie du cloud
27 mai 2026

L'Observabilité : Un Pilier Essentiel dans l’adoption du Cloud et des architectures modernes
31 octobre 2024
Veille craft, cloud & archi
Le meilleur de nos articles, une fois par mois.
Je m'abonneDésabonnement en 1 clic. Pas de partage de données.
Cet article vous a inspiré ?
Vous avez des questions ou des défis techniques suite à cet article ? Nos experts sont là pour vous aider à trouver des solutions concrètes à vos problématiques.