Bref, j’ai mis en place les DORA Metrics dans un grand groupe ! (REX 🦖)

Nouvel article qui fait suite à mon introduction aux DORA Metrics 🎉 Pour rappel, je vous avais défini les 4 métriques (4 Keys) qui permettent de mesurer l'efficacité de la livraison logicielle:
Deployment Frequency | Lead Time for Changes | Mean Time to Restore | Change Failure Rate
Aujourd'hui, je vous partage mon retour d'expérience (REX) sur leur mise en place chez un client qui souhaitait objectiver et améliorer sa performance de livraison.
1. Comprendre l'organisation et définir les concepts 🏢
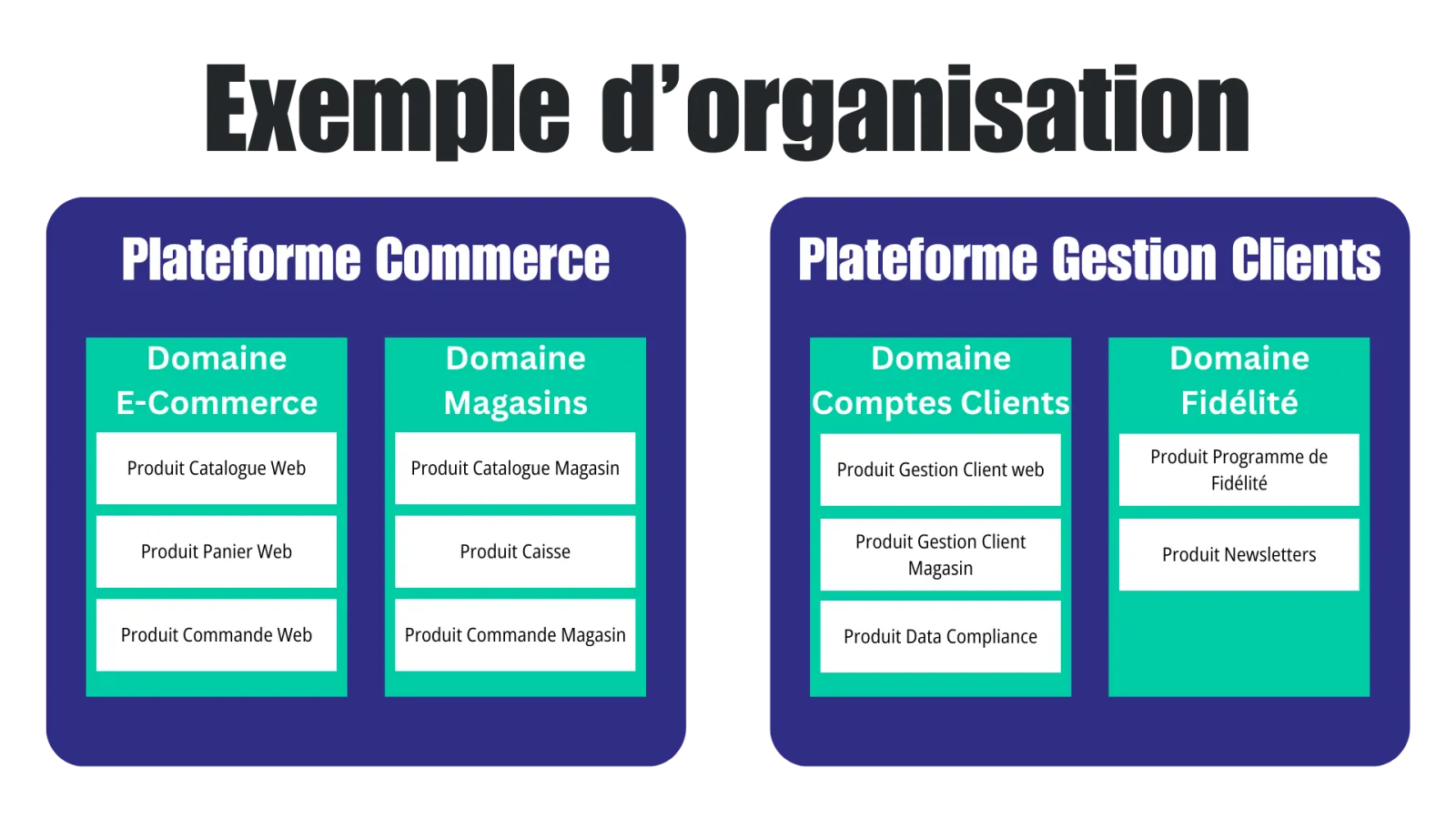
L'organisation du groupe
Lorsque je suis arrivé chez ce client, j'ai pu constater qu'il y avait de nombreux produits (> 1000) avec des technologies hétérogènes. Mais d'ailleurs, c'est quoi un produit ? La première chose à faire a été de se mettre d'accord sur les définitions !
L'organisation de l'entreprise était la suivante :
- Le groupe est divisé en plateformes
- Les plateformes sont divisées en domaines
- Les domaines sont divisés en produits
Après quelques ateliers avec le management et des projets pilotes, nous sommes tombés d'accord sur les définitions suivantes :
- Plateforme : Niveau le plus haut de l'organisation, regroupe plusieurs domaines fonctionnels liés
- Domaine : Regroupe des produits ayant des fonctionnalités similaires ou complémentaires
- Produit : Périmètre fonctionnel perceptible par l'utilisateur final, pour lequel les changements lui sont communiqués. Un produit peut être composé de plusieurs composants (microservices ou briques monolithiques) et peut être déployé sur différents environnements de production
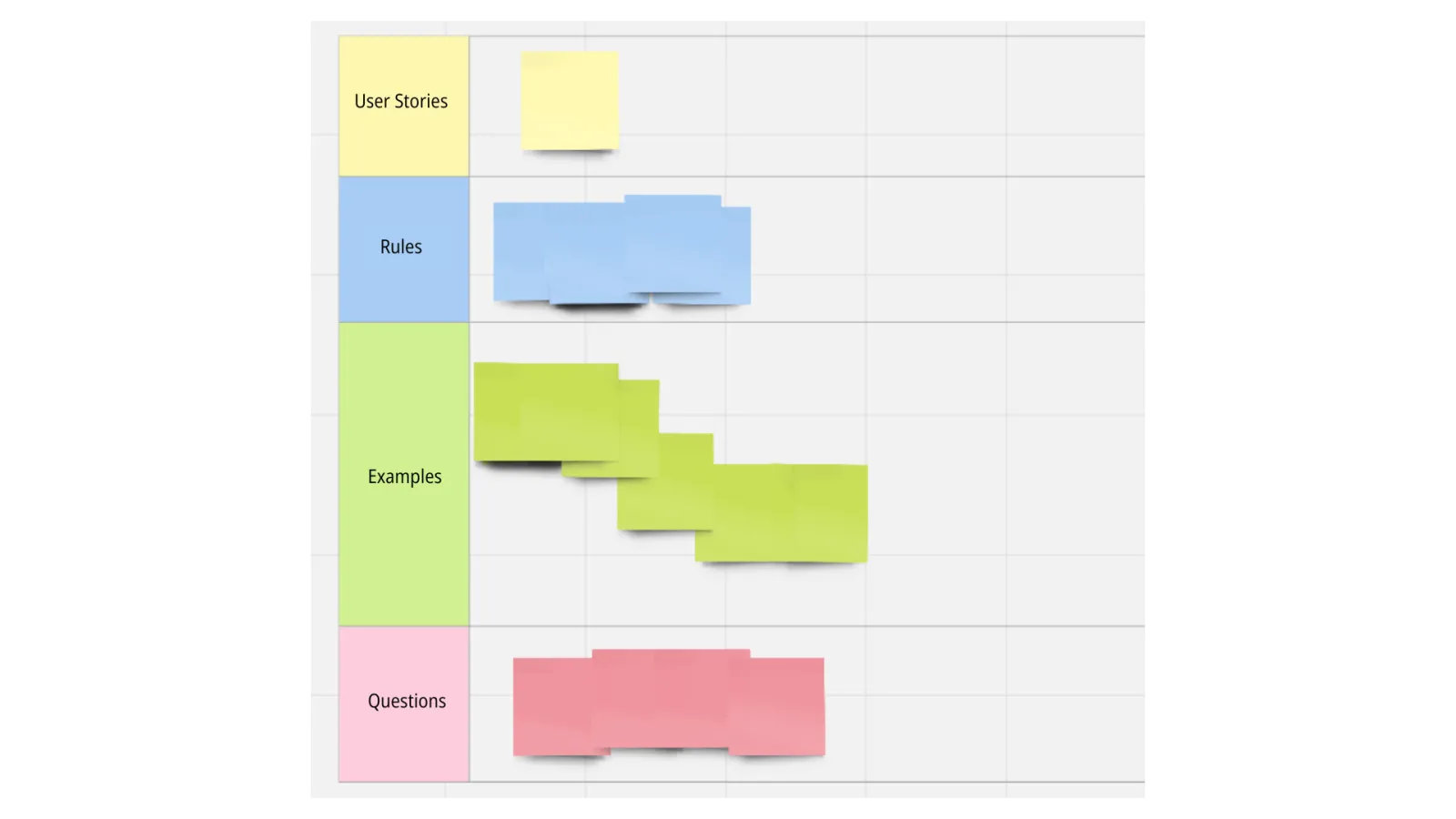
Les cas d'usage identifiés
Une fois l'organisation de la société comprise et les concepts définis, il a fallu comprendre tous les cas d'usage des DORA Metrics avec des ateliers comme l'Example Mapping.
ℹ️ N’hésitez pas à consulter notre offre de formations si vous souhaitez approfondir vos connaissances Craft et pratiquer ce type d’atelier.
Je ne veux pas vous mettre tous les cas d'usage, car ça serait trop long et ce n'est pas l'objectif de l'article, mais je vais vous donner quelques exemples :
- En tant que CTO, je souhaite comparer les performances de livraison entre les plateformes (par exemple entre la plateforme Commerce et la plateforme Gestion Clients) pour identifier les meilleures pratiques DevOps à généraliser au niveau du groupe.
- En tant que Lead Tech d'un produit e-commerce, je souhaite comparer nos métriques avec celles des autres produits du domaine Commerce (comme le panier ou le catalogue) pour comprendre pourquoi leurs déploiements génèrent moins d'incidents en production.
- En tant que Domain Leader Catalogue, je souhaite analyser l'impact du multi-instance sur la fréquence de déploiement. Par exemple, comprendre si les produits déployés sur plusieurs environnements de production (pour différentes BU) ont plus de difficultés à maintenir un rythme de livraison élevé et si oui, comprendre les causes.
- En tant que Product Owner, je veux suivre l'évolution de nos métriques après le passage d'une architecture monolithique à des microservices, notamment pour vérifier si la fréquence de déploiement de chaque composant s'améliore comme prévu.
2. Les défis techniques et organisationnels 🔧
La mise en place des DORA Metrics dans un groupe de cette taille présentait beaucoup de défis majeurs. Avec mon client, nous avons fait le choix d'implémenter les DORA Metrics uniquement sur les produits déployés sur Kubernetes (cela représente environ 80% des produits). Voici les principaux obstacles que nous avons dû surmonter :
Une architecture complexe à appréhender
L'entreprise comportait :
- Plus de 1000 produits utilisant des technologies différentes
- Des produits déployés plusieurs fois pour différentes BU
- Un mix d'architectures monolithiques et microservices
- Des relations complexes entre composants et produits
Face à cette complexité, nous avons adopté une approche pragmatique : sélectionner quelques produits pilotes représentatifs de l'écosystème pour implémenter les DORA Metrics. Après avoir validé notre méthodologie sur ces cas concrets, nous avons pu déployer progressivement la solution à l'ensemble du portefeuille de produits.
Des données éparpillées
Il fallait collecter les données depuis :
- Les clusters Kubernetes pour les logs de déploiements
- GitHub pour l'historique des versions
- ServiceNow pour les incidents
Le véritable défi ? Corréler ces données hétérogènes pour obtenir une vision cohérente !
Cette mission a nécessité une collaboration transverse entre plusieurs équipes techniques. Nous avons conçu une architecture cloud robuste pour centraliser l'ensemble des données dans une base de données BigQuery. Cette solution nous a d'ailleurs poussés à optimiser nos requêtes et l'utilisation de BigQuery car nous atteignions rapidement les limites de performance 😅.
L'objectif final était de disposer d'un référentiel unique permettant d'exécuter des requêtes SQL complexes (cf l’implémentation des métriques plus bas dans cet article) pour calculer précisément nos métriques DORA.
Des pratiques DevOps non standardisées
Une partie des équipes avait :
- Leur propre workflow de déploiement
- Leurs conventions de versioning
- Leur façon de gérer les environnements de production
Il a fallu aider ces équipes à adopter les bonnes pratiques du groupe à savoir :
- la norme SemVer pour le versioning
- l'utilisation des solutions groupe pour déployer leurs produits sur Kubernetes
- la déclaration systématique des incidents dans ServiceNow
- etc.
La standardisation des pratiques DevOps : un prérequis indispensable aux DORA Metrics
Ce chantier d'harmonisation, bien que colossal pour une organisation de cette envergure, s'est révélé être un puissant levier de transformation ! Même si des standards existaient déjà, les DORA Metrics ont agi comme un révélateur implacable : les projets ne respectant pas les bonnes pratiques étaient immédiatement identifiables par l'absence de données exploitables pour le calcul des métriques.
Cette transparence a créé une incitation naturelle à l'adoption des standards du groupe, bien plus efficace qu'une simple directive top-down.
Des données pas toujours fiables
Les principaux problèmes :
- Pas de standard dans le nommage des composants
- Des déploiements de configuration qui polluaient les métriques
- Une difficulté à identifier les vrais déploiements en production
- Des annotations manquantes ou incohérentes
Pragmatisme et itération : la clé du succès en environnement réel
Face à l'imperfection inévitable des données en contexte d'entreprise de grande taille, nous avons adopté une approche pragmatique : formuler des hypothèses clairement documentées et acceptées par toutes les parties prenantes. Ces conventions, bien qu'imparfaites, nous ont permis d'avancer sans attendre la perfection qui arrivera sans doute jamais.
Cette démarche s'alignait parfaitement avec la philosophie des DORA Metrics : l'objectif n'est pas d'atteindre une précision absolue, mais de capturer des tendances significatives permettant d'orienter l'amélioration continue.
Une organisation multi-niveaux à respecter
Il fallait :
- Fournir des vues adaptées à chaque niveau (plateforme, domaine, produit)
- Prendre en compte les particularités de chaque BU
- Garder des métriques comparables malgré les différences
- Accompagner les équipes vers de meilleures pratiques
La dimension humaine à ne pas négliger
Nous avons rapidement identifié des craintes légitimes :
- Peur d'être jugé uniquement sur des chiffres et que les métriques servent à comparer les équipes entre elles
- Tentation de biaiser le système (par exemple en multipliant volontairement les déploiements inutiles pour améliorer artificiellement la fréquence)
- Réticence à reporter certains incidents pour ne pas impacter le Change Failure Rate
- Difficultés à voir les DORA metrics comme outil d'amélioration continue
Notre approche : transformer les résistances en adhésion
Plutôt que d'imposer un système de mesure, nous avons choisi d'impliquer les équipes dans sa construction. Nous avons organisé des ateliers de sensibilisation, partagé les objectifs stratégiques derrière ces métriques, et surtout, écouté les préoccupations des équipes.
Cette démarche participative a permis de transformer progressivement la perception des DORA Metrics : d'un outil potentiellement menaçant de surveillance, elles sont devenues un levier d'amélioration continue valorisé par les équipes elles-mêmes.
3. Hypothèses techniques retenues 🧐
Fondations solides : établir des conventions claires et partagées Pour bâtir un système de mesure fiable dans un environnement complexe, nous avons dû établir un ensemble d'hypothèses et de conventions. Elles ont été clairement documentées et validées collectivement et elles étaient nécessaires pour calculer les métriques avec des données imparfaites.
Voici les principales conventions que nous avons établies, organisées par domaine :
Déploiements 🚀
Identification des déploiements en production
- Un déploiement est considéré réussi uniquement quand :
- Seuls les déploiements avec l'annotation
info/environment = prodsont pris en compte - Les déploiements de configuration pure sont exclus des métriques
Impact utilisateur
- Un déploiement en production impacte potentiellement l'utilisateur final
- Un produit peut être déployé sur plusieurs workspaces (namespace/cluster)
- Une modification d'un composant ou de sa configuration implique une modification du produit
Lead Time For Changes ⏱️
Traçabilité du code
- Le code source mentionné dans l'annotation est responsable du déploiement du composant
- La correspondance dans le repository Git est matérialisée par un tag
- Le temps entre un commit et son tag est négligeable pour le calcul global
Limitations acceptées
- Seuls les tags respectant la norme SemVer sont pris en compte
- Les configurations d'environnement sans code source associé créent des déploiements multiples pour une même version
Incidents et récupération 🚨
Temporalité des incidents
- Le temps entre l'apparition réelle d'un incident et son ouverture dans l'outil est considéré comme négligeable
- Tous les incidents reportés (automatiquement ou manuellement) ont un impact utilisateur
Association déploiement-incident
- Le déploiement le plus récent d'un composant du produit avant la création de l'incident est considéré comme la cause
- En l'absence d'information sur l'instance spécifique, l'incident est associé au produit dans son ensemble
Structure organisationnelle 🏢
Définition d'un produit
- Un produit est un périmètre fonctionnel perceptible par l'utilisateur final
- Un produit peut être composé de plusieurs composants (microservices ou briques monolithiques)
- Les changements au niveau produit sont communiqués aux utilisateurs
Multi-instance
- Un même produit peut être déployé dans différents environnements de production
- Chaque instance est considérée comme une entité distincte pour les métriques de déploiement
- Les incidents sont agrégés au niveau produit plutôt qu'au niveau instance
Limitations connues 🚧
Données manquantes
- Certains déploiements peuvent manquer d'annotations complètes
- Les tags peuvent ne pas suivre strictement SemVer
- La corrélation entre incidents et instances spécifiques n'est pas toujours possible
Pistes d'amélioration
- Implémenter "configuration as code" pour mieux tracer les changements de configuration
- Étendre la prise en compte des tags au-delà de SemVer
- Ajouter la notion d'instance produit dans l'outil de gestion des incidents
Ces hypothèses sont régulièrement revues et ajustées en fonction des retours d'expérience et de l'évolution des pratiques DevOps dans l'organisation.
4. La collecte des données : une approche par source 📊
L'architecture de collecte : le cœur technique du projet Le succès des DORA Metrics repose sur notre capacité à collecter, intégrer et corréler des données provenant de multiples systèmes. Cette architecture d'intégration constitue la colonne vertébrale technique de notre solution.
Architecture de données centralisée
BigQuery comme référentiel central
Pour répondre aux besoins d'analyse et de corrélation des données, nous avons mis en place une architecture où toutes les données sont centralisées dans Google BigQuery. Cette approche présente plusieurs avantages :
- Capacité à traiter de grands volumes de données (logs Kubernetes, événements GitHub, tickets ServiceNow)
- Possibilité d'exécuter des requêtes SQL complexes pour calculer les métriques
- Facilité d'intégration avec des outils de visualisation (pour ce projet, Power BI)
- Mise à jour des données en quasi temps réel via des flux de données (streaming)
Examinons maintenant notre approche pour chaque source de données :
Données de déploiement
| Élément | Description |
|---|---|
| Source principale | Kubernetes |
| Événements collectés |
|
| Annotations existantes sur les pods |
|
| Annotations à ajouter pour les DORA |
|
| Points d’attention |
|
Données de code source
| Élément | Description |
|---|---|
| Source de vérité | GitHub |
| Sources d’extraction |
|
| Corrélation version-déploiement |
|
Données d'incidents
| Élément | Description |
|---|---|
| Source principale | ServiceNow |
| Critères de sélection des incidents |
|
| Limitations actuelles |
|
5. Implémentation et calcul des métriques 📈
De la théorie à la pratique : adapter et calculer les métriques à tous les niveaux Les définitions théoriques des DORA Metrics sont un point de départ, mais leur implémentation concrète nécessite une adaptation fine au contexte spécifique de l'entreprise et une approche multi-échelle pour répondre aux besoins de tous les niveaux de l'organisation.
Implémentation des métriques
Voici comment nous avons adapté et implémenté chacune des quatre métriques :
Lead Time for Changes (Délai de livraison des changements)
Le Lead Time for Changes mesure le temps qui s'écoule entre la dernière modification de code (commit) et son déploiement effectif en production. Dans cette entreprise, nous avons dû sensibiliser les équipes sur l'importance de taguer chaque version déployée pour tracer correctement le code source.
- Extraction: à partir des déploiements Kubernetes (annotation "version" et "repo"), nous retrouvons le commit Git.
- Calcul:
- Agrégation: comme chaque produit pouvait regrouper plusieurs composants, nous avons choisi de calculer d'abord un Lead Time moyen pour chaque composant, avant de prendre la moyenne de ces composants au niveau du produit.
Principale difficulté: éviter les déploiements de "configuration" sans changement de code, qui fausseraient la métrique. Nous avons donc isolé ces cas dans un tableau de bord à part, pour ne pas influencer le Lead Time for Changes général.
Deployment Frequency (Fréquence de déploiement)
La Deployment Frequency indique la cadence à laquelle on pousse des mises à jour en production (exprimée en , ou inverse de l'intervalle entre deux déploiements).
Au niveau d'un produit, nous calculons la moyenne des fréquences de déploiement de tous ses composants. Nous avons aussi mis en évidence quelques "cas limites", par exemple lorsqu'un composant n'a qu'un seul déploiement. Dans ces situations, on ne peut pas déterminer d'intervalle et la fréquence reste "N/A".
C'était essentiel de distinguer un déploiement réellement exposé à l'utilisateur dans l'environnement "prod" (annotation "info/environment=prod") de simples déploiements sur des environnements de test ou d'intégration.
Mean Time to Restore (MTTR) ou Mean Time to Recover (Temps moyen de restauration)
Le MTTR calcule le temps moyen nécessaire pour résoudre un incident ou le temps apparent de défaillance pour l'utilisateur. Au départ, nous avons constaté que l'outil de ticketing (ServiceNow) n'enregistrait pas toujours les champs d'ouverture et de clôture de manière cohérente.
Nous avons donc dû :
- Sensibiliser les équipes support : un champ "date de début d'incident" doit être rempli le plus précisément possible dès ouverture (sinon nous utilisons la date de création du ticket).
- Vérifier la date de résolution ou de clôture : c'est la référence pour la fin d'incident.
- Calculer la moyenne de (date de fin − date de début) sur tous les incidents clôturés, pour chaque produit.
Pour la plupart des cas, cela a fonctionné correctement. Mais, comme souvent, nous avons rencontré des écarts (tickets fermés très tardivement, incidents mal catégorisés, etc.). Il a fallu faire accepter les limites de la mesure (la durée de vie d'un ticket n'est pas toujours égale à la durée réelle de l'incident technique).
Change Failure Rate (Taux d'échec des changements)
Le Change Failure Rate (CFR) représente la proportion de déploiements qui entraînent au moins un incident en production. Ici, le plus gros challenge a été de lier les incidents ServiceNow au "dernier déploiement" d'un produit. Faute de pouvoir tracer précisément l'instance de composant à l'origine, nous avons adopté la convention suivante :
- Identifier le "dernier déploiement" survenu avant la date de création de l'incident, tous composants du produit confondus.
- Incrémenter un déploiement "défaillant" si au moins un incident lui est rattaché.
- Diviser le nombre de déploiements défaillants par le nombre total de déploiements du produit, sur la période considérée.
Bien sûr, cela reste une approximation: on ne sait pas distinguer un incident réellement lié à un composant particulier. D'où la nécessité d'améliorer la remontée d'informations dans ServiceNow (par exemple en demandant explicitement quelle version réelle est touchée).
Calcul des métriques par niveau de granularité 📊
Vision multi-échelle : du composant à la plateforme L'une des forces de notre implémentation réside dans sa capacité à fournir des métriques à différents niveaux de granularité. Cette approche multi-échelle permet à chaque niveau de management d'accéder aux indicateurs pertinents pour son périmètre de responsabilité, tout en garantissant la cohérence globale des mesures.
Différentes vues des Dora Metrics de notre solution pour illustrer les calculs un peu plus bas.
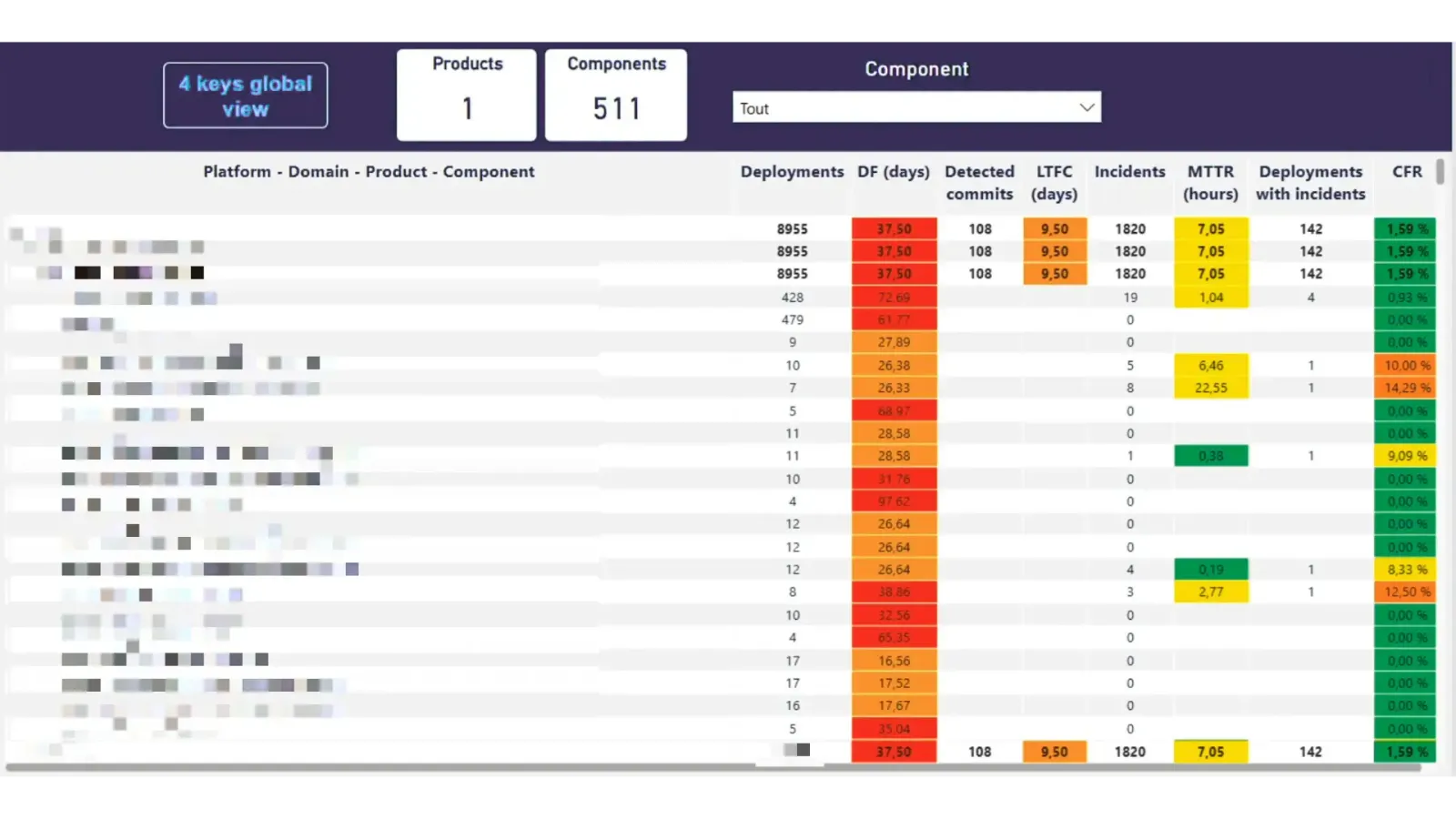
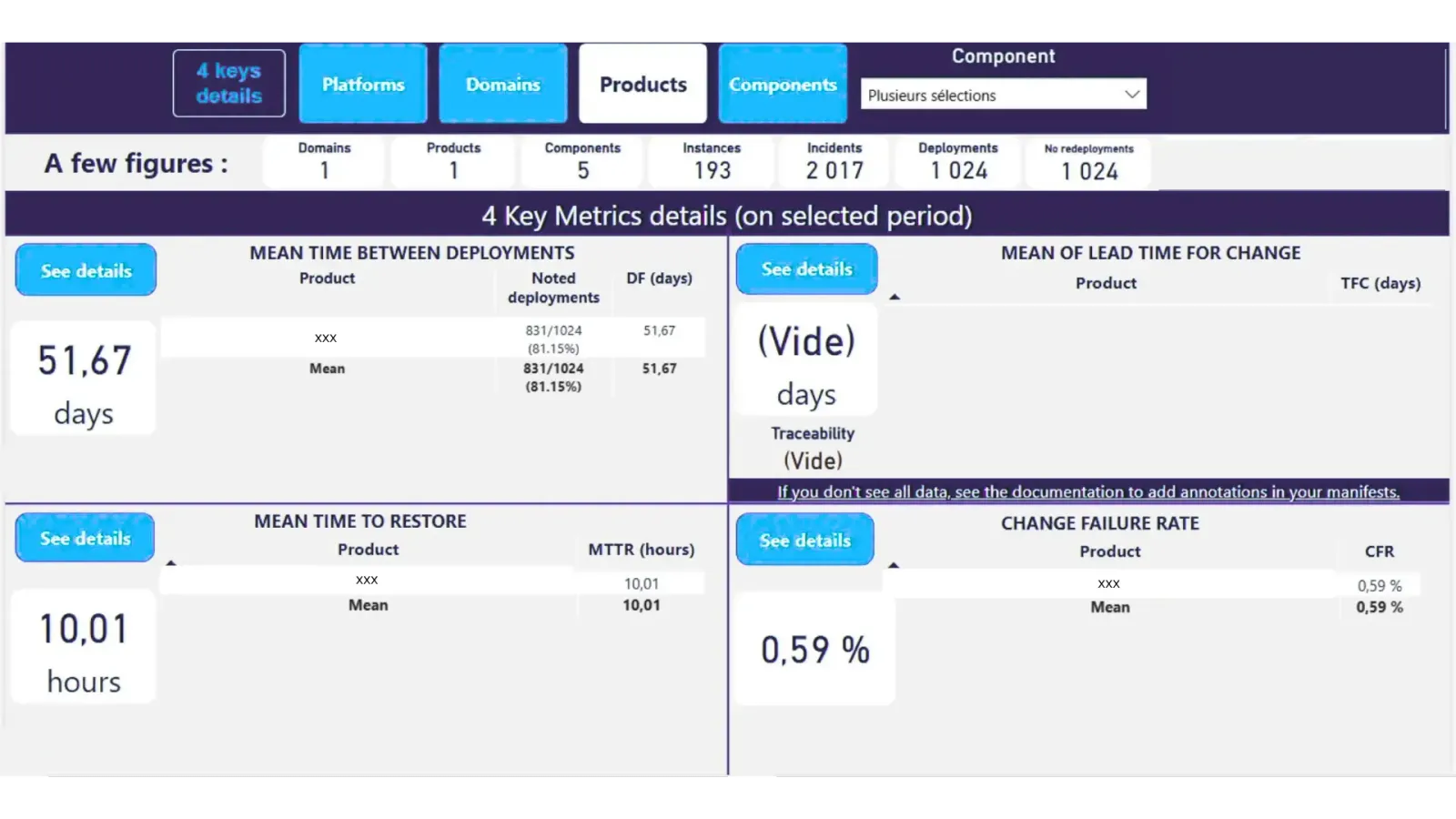
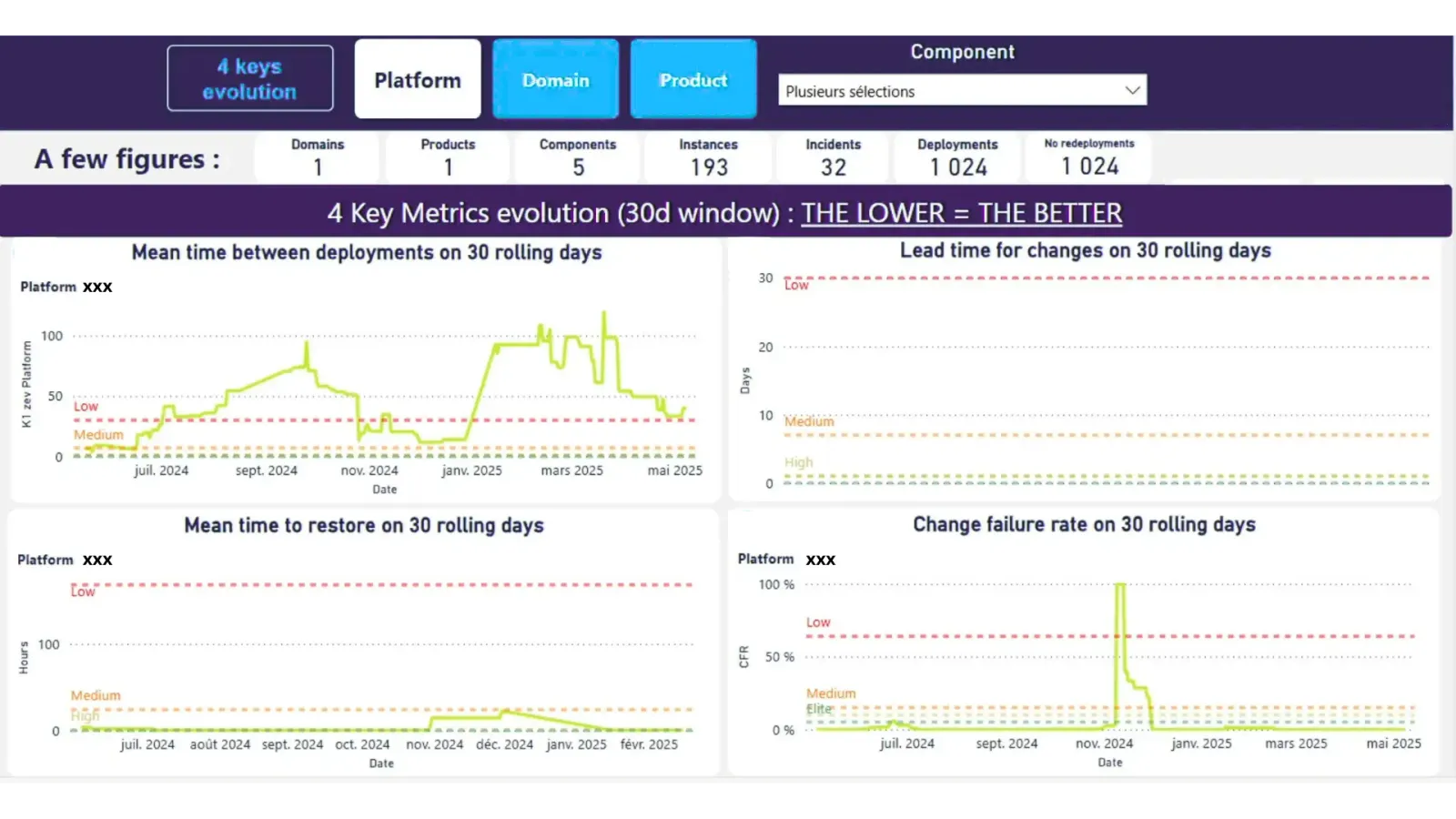
Lead Time For Changes
Niveau Composant
où :
- = Date de déploiement en production
- = Date du dernier commit de la version
- = Nombre de déploiements en production associés à un tag Git
Niveau Produit
où :
- = Lead Time du composant i
- = Nombre de composants du produit
Niveau Domaine
où :
- = Lead Time du produit i
- = Nombre de produits dans le domaine
Niveau Plateforme
où :
- = Lead Time du domaine i
- = Nombre de domaines dans la plateforme
Deployment Frequency
Niveau Composant
où :
- = Date du déploiement actuel
- = Date du déploiement précédent
Niveau Produit
où :
- = Nombre de déploiements composants
- = Fréquence de déploiement du composant
Niveau Domaine
où :
- = Nombre de produits
- = Fréquence de déploiement du produit
Niveau Plateforme
où :
- = Nombre de domaines
- = Fréquence de déploiement du domaine
Change Failure Rate
Niveau Composant
- Non calculé à ce niveau en raison de la difficulté à associer précisément les incidents à des composants spécifiques
Niveau Produit
où :
- = Nombre de déploiements précédant au moins un incident
- = Nombre total de déploiements du produit
Niveau Domaine
où :
- = Nombre de produits dans le domaine
Niveau Plateforme
où :
- = Nombre de domaines dans la plateforme
Mean Time To Recover
Niveau Composant
- Non calculé à ce niveau car les incidents sont tracés au niveau produit
Niveau Produit
où :
- = Nombre d'incidents
- = Date de résolution de l'incident
- = Date de début de l'incident
Niveau Domaine
où :
- = Nombre de produits dans le domaine
Niveau Plateforme
où :
- = Nombre de domaines dans la plateforme
Calcul des métriques avec BigQuery

Photo by Taylor Vick on Unsplash
Toutes nos métriques sont calculées via des requêtes SQL exécutées sur BigQuery. Voici comment nous procédons pour chaque métrique :
Lead Time For Changes
- Mesure le temps entre une modification de code et son déploiement en production
- Formule :
-- Calcul du Lead Time For Changes par composant
SELECT d.component_name,
d.product_id,
AVG(TIMESTAMP_DIFF(d.deployment_timestamp, c.commit_timestamp, HOUR)) as lead_time_hours
FROM `dora_metrics.deployments` d
JOIN
`dora_metrics.git_commits` c
ON
d.git_tag = c.tag
WHERE d.environment = 'prod'
AND d.deployment_timestamp BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY d.component_name, d.product_id
Deployment Frequency
- Fréquence des déploiements en production
- Calculée par composant puis agrégée au niveau produit
- Exclusion des déploiements de configuration
-- Calcul de la fréquence de déploiement par composant
WITH deployments_ordered AS (SELECT component_name,
product_id,
deployment_timestamp,
LAG(deployment_timestamp) OVER (
PARTITION BY component_name
ORDER BY deployment_timestamp
) as previous_deployment
FROM `dora_metrics.deployments`
WHERE environment = 'prod'
AND is_config_only = FALSE
AND deployment_timestamp BETWEEN '2024-01-01' AND '2024-12-31')
SELECT component_name,
product_id,
COUNT(*) as deployment_count,
AVG(TIMESTAMP_DIFF(deployment_timestamp, previous_deployment, DAY)) as avg_days_between_deployments,
SAFE_DIVIDE(COUNT(*), 365) as deployments_per_day
FROM deployments_ordered
WHERE previous_deployment IS NOT NULL
GROUP BY component_name, product_id
Change Failure Rate
- Taux de déploiements causant au moins un incident en production
- Exprimé en pourcentage
- Basé sur les déploiements Kubernetes réussis et les incidents ServiceNow résolus
-- Calcul du Change Failure Rate par produit
WITH deployments_with_incidents AS (SELECT d.deployment_id,
d.product_id,
MAX(CASE WHEN i.incident_id IS NOT NULL THEN 1 ELSE 0 END) as has_incident
FROM `dora_metrics.deployments` d
LEFT JOIN
`dora_metrics.incidents` i
ON
d.product_id = i.product_id
AND i.created_timestamp > d.deployment_timestamp
AND i.created_timestamp <= (SELECT MIN(next_d.deployment_timestamp)
FROM `dora_metrics.deployments` next_d
WHERE next_d.product_id = d.product_id
AND next_d.deployment_timestamp > d.deployment_timestamp)
WHERE d.environment = 'prod'
AND d.deployment_timestamp BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY d.deployment_id, d.product_id)
SELECT product_id,
COUNT(*) as total_deployments,
SUM(has_incident) as failed_deployments,
SAFE_DIVIDE(SUM(has_incident), COUNT(*)) * 100 as change_failure_rate_percent
FROM deployments_with_incidents
GROUP BY product_id
Mean Time To Recover
- Temps moyen de résolution des incidents
- Calculé à partir des dates d'ouverture et de résolution dans ServiceNow
- Agrégé au niveau produit
-- Calcul du Mean Time To Recover par produit
SELECT product_id,
COUNT(*) as incident_count,
AVG(TIMESTAMP_DIFF(resolved_timestamp, created_timestamp, HOUR)) as mttr_hours
FROM `dora_metrics.incidents`
WHERE status = 'Resolved'
AND created_timestamp BETWEEN '2024-01-01' AND '2024-12-31'
AND resolved_timestamp IS NOT NULL
GROUP BY product_id
Fiabilisation et optimisation des données
Infrastructure as Code
- Utilisation de Terraform pour standardiser les déploiements
- Configuration automatique des annotations requises
- Validation des formats de données
Bonnes pratiques
- Tagging systématique des versions
- Documentation des conventions
- Formation des équipes
Monitoring
- Détection des annotations manquantes
- Alertes sur les incohérences
- Suivi de la qualité des données
Optimisation de BigQuery
La gestion d'un volume important de données dans BigQuery a nécessité plusieurs optimisations :
-- Création de tables partitionnées par date pour améliorer les performances
CREATE TABLE `dora_metrics.deployments_partitioned`
PARTITION BY DATE
(
deployment_timestamp
)
AS
SELECT *
FROM `dora_metrics.deployments`;
-- Création de vues matérialisées pour les requêtes fréquentes
CREATE
MATERIALIZED VIEW `dora_metrics.lead_time_daily`
AS
SELECT product_id, DATE (deployment_timestamp) as deployment_date, AVG (TIMESTAMP_DIFF(deployment_timestamp, commit_timestamp, HOUR)) as avg_lead_time_hours
FROM
`dora_metrics.deployments_with_commits`
GROUP BY
product_id, deployment_date;
Automatisation des flux de données
Nous avons mis en place plusieurs processus automatisés pour maintenir des données à jour :
- Jobs Cloud Functions pour synchroniser les données ServiceNow toutes les 15 minutes
- Webhooks GitHub pour capturer les événements de commit et de tag en temps réel
- Export des logs Kubernetes via Cloud Logging avec un délai maximum de 5 minutes
Cette approche nous permet d'obtenir des métriques fiables et exploitables pour l'amélioration continue de nos processus de livraison.
Points clés pour l'agrégation 🔑
Garantir la cohérence et la pertinence des métriques agrégées
- Pondération
- Exclusions
- Cas particuliers
Cette approche d'agrégation garantit :
- Une représentation équitable à chaque niveau
- Une cohérence dans le calcul des métriques
- Une prise en compte appropriée des cas limites
Synthèse de notre approche d'implémentation
Une implémentation progressive et adaptée au contexte
Notre approche d'implémentation des DORA Metrics a combiné rigueur méthodologique et pragmatisme. Nous avons défini des formules de calcul précises tout en les adaptant aux réalités opérationnelles de l'entreprise. L'agrégation multi-niveaux nous a permis de répondre aux besoins de tous, du développeur individuel jusqu'au comité de direction.
Cette implémentation technique n'était cependant que la première étape. La véritable valeur des DORA Metrics réside dans leur capacité à transformer les pratiques et la culture de l'organisation.
6. Bénéfices, enseignements et perspectives 🤔
La mise en place des DORA Metrics est un voyage, pas une destination.
Ce retour d'expérience illustre une réalité fondamentale : implémenter les DORA Metrics dans un grand groupe nécessite bien plus qu'une simple application de formules mathématiques. C'est un projet de transformation qui touche à la fois aux aspects techniques, organisationnels et humains.
Bénéfices observés
Impact transformationnel : au-delà des chiffres
L'implémentation des DORA Metrics a généré des bénéfices qui dépassent largement le cadre de la simple mesure de performance. Elle a catalysé une véritable transformation des pratiques et de la culture de livraison logicielle au sein de l'organisation.
Voici les principaux impacts positifs observés :
- Une meilleure visibilité sur la performance de livraison : Les équipes ont pu objectiver leurs points forts (par exemple, une fréquence de déploiement élevée) et leurs axes d'amélioration (par exemple, un très long "Lead Time for Changes").
- Un langage commun entre équipes : Les DORA Metrics servent désormais de référence partagée. Lorsqu'il y a un incident, tout le monde comprend la corrélation possible entre le "dernier déploiement" et le Change Failure Rate.
- La mise en lumière de la dette de traçabilité : Le besoin de taguer systématiquement les versions, d'indiquer l'instance concernée dans les tickets, etc. a été rendu évident grâce à la mesure du Lead Time for Changes et du Change Failure Rate.
Ces métriques sont imparfaites (comme tout indicateur), mais elles offrent un "socle" suffisamment solide pour enclencher de vraies discussions et pour s'améliorer en continu.
Enseignements clés
Cette expérience a impliqué de nombreuses adaptations et m'a permis de tirer plusieurs enseignements importants :
- Standardisation nécessaire : Les DORA Metrics nécessitent une standardisation des pratiques DevOps pour être efficaces
- Adaptation au contexte : Il est essentiel d'adapter les métriques au contexte spécifique de l'entreprise
- Qualité des données cruciale : La fiabilité des métriques dépend directement de la qualité des données collectées
- Dimension humaine prépondérante : L'accompagnement des équipes et la gestion du changement sont aussi importants que l'aspect technique
- Pragmatisme indispensable : Accepter les imperfections initiales et itérer progressivement est la clé du succès
Perspectives d'évolution
Cette première phase d'implémentation nous a permis d'identifier plusieurs axes d'amélioration pour l'avenir :
- Détection des changements de Configuration : Déployer une solution pour tracer précisément les modifications de configuration, actuellement difficiles à distinguer des déploiements de code.
- Granularité des incidents : Enrichir ServiceNow pour associer chaque incident au composant ou à l'instance spécifique concernée, permettant ainsi un calcul plus précis du Change Failure Rate.
- Automatisation accrue : Réduire les interventions manuelles dans la collecte et le traitement des données pour améliorer la fiabilité et la fréquence de mise à jour des métriques.
Conclusion 🙌
Ce retour d'expérience démontre que la mise en place des DORA Metrics dans un grand groupe est un projet de transformation à part entière. Au-delà des aspects techniques, c'est avant tout un projet humain qui nécessite pédagogie, pragmatisme et persévérance.
Le parcours n’a pas été sans difficultés. Il y des inquiétudes, notamment parmi les personnes directement impliquées dans les projets. Grâce à des sponsors engagés et, surtout, à une approche basée sur la transparence et le temps accordé à chacun, nous avons pu atteindre nos objectifs.
Les bénéfices sont à la hauteur de l'investissement : une meilleure visibilité sur la performance de livraison, un langage commun entre les équipes, et surtout, une culture d'amélioration continue qui s'installe progressivement dans l'organisation.
J'espère que ce partage d'expérience vous sera utile ! N'hésitez à me contacter sur Linkedin ou par mail si vous souhaitez échanger sur le sujet 🙂
À propos de l'auteur

Articles connexes

DORA Metrics : Évaluer la performance de livraison logicielle
31 octobre 2024

Platform Engineering : L’art de dompter l’entropie du cloud
27 mai 2026
Connecter Datadog à un réseau 100% hors-ligne : retour d'expérience avec Vector
31 mars 2026

DORA Metrics x Datadog : Piloter sa vélocité sans effort
19 mars 2026
Veille craft, cloud & archi
Le meilleur de nos articles, une fois par mois.
Je m'abonneDésabonnement en 1 clic. Pas de partage de données.
Cet article vous a inspiré ?
Vous avez des questions ou des défis techniques suite à cet article ? Nos experts sont là pour vous aider à trouver des solutions concrètes à vos problématiques.